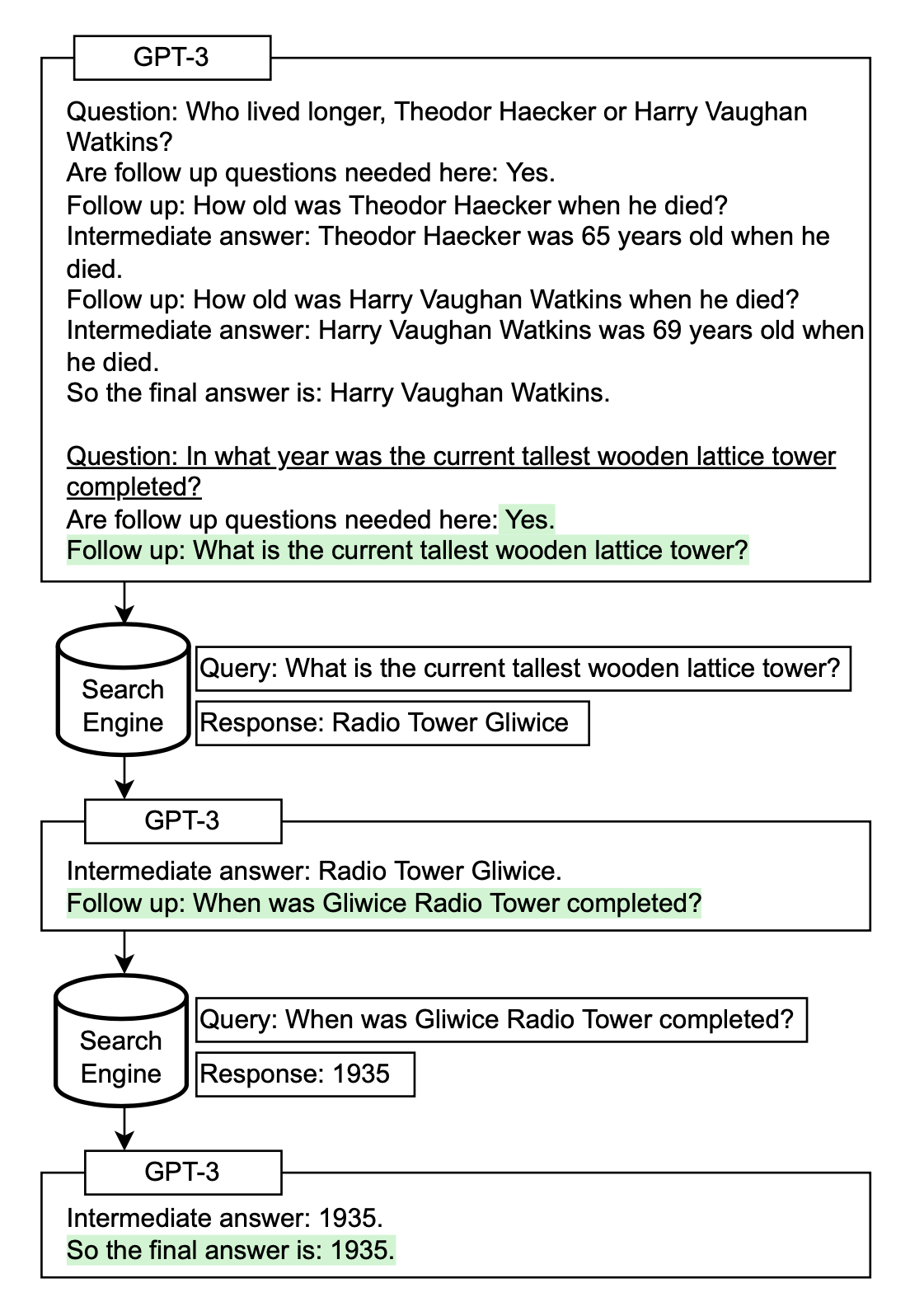
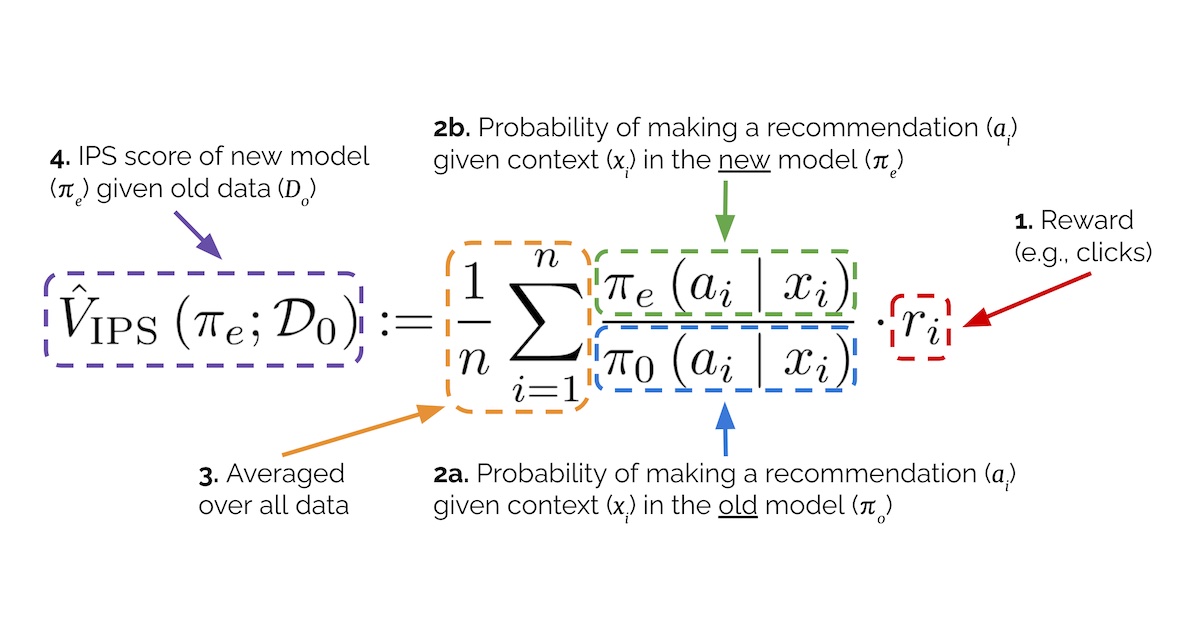
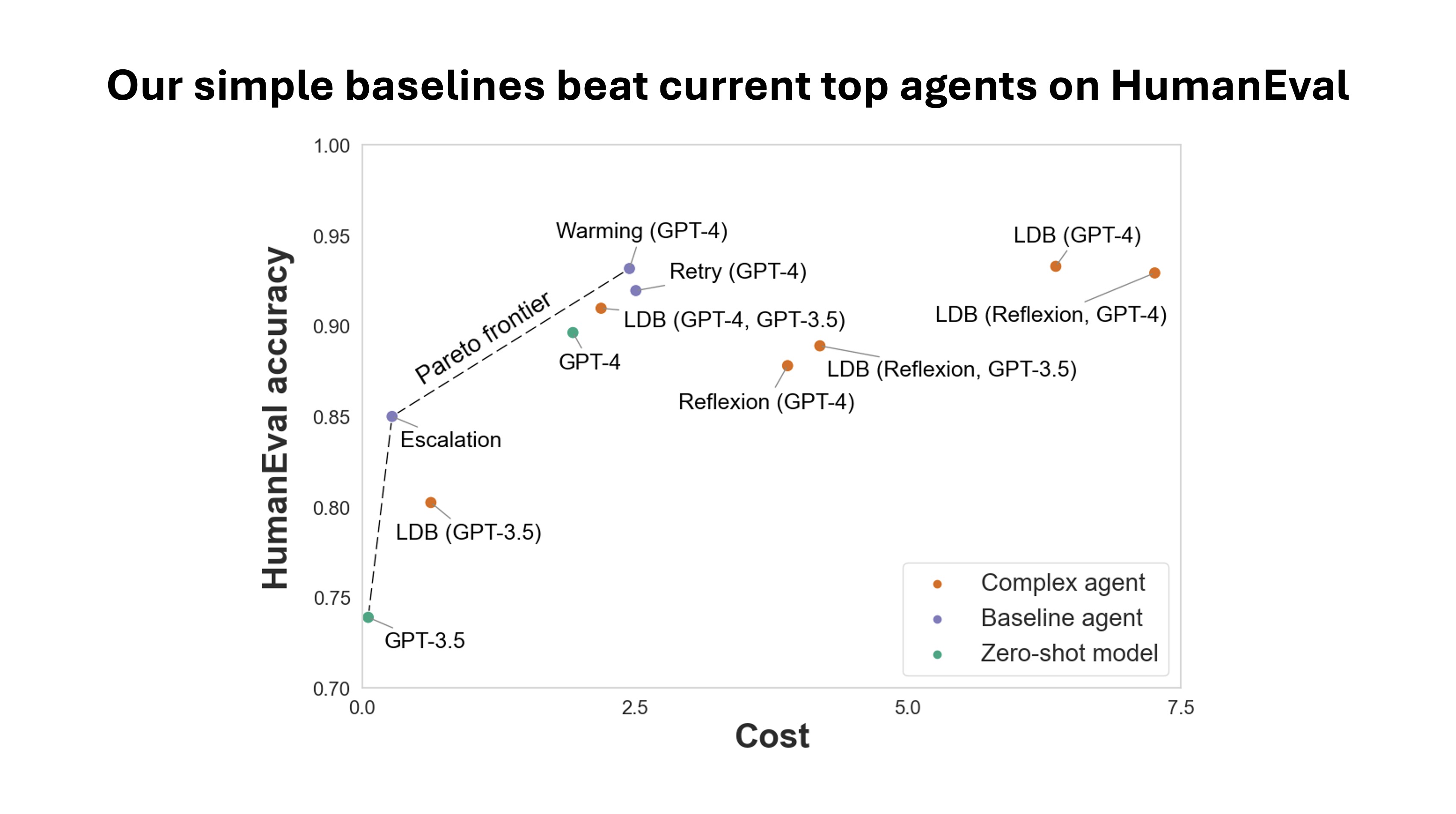
AI leaderboards are no longer useful. It's time to switch to Pareto curves.
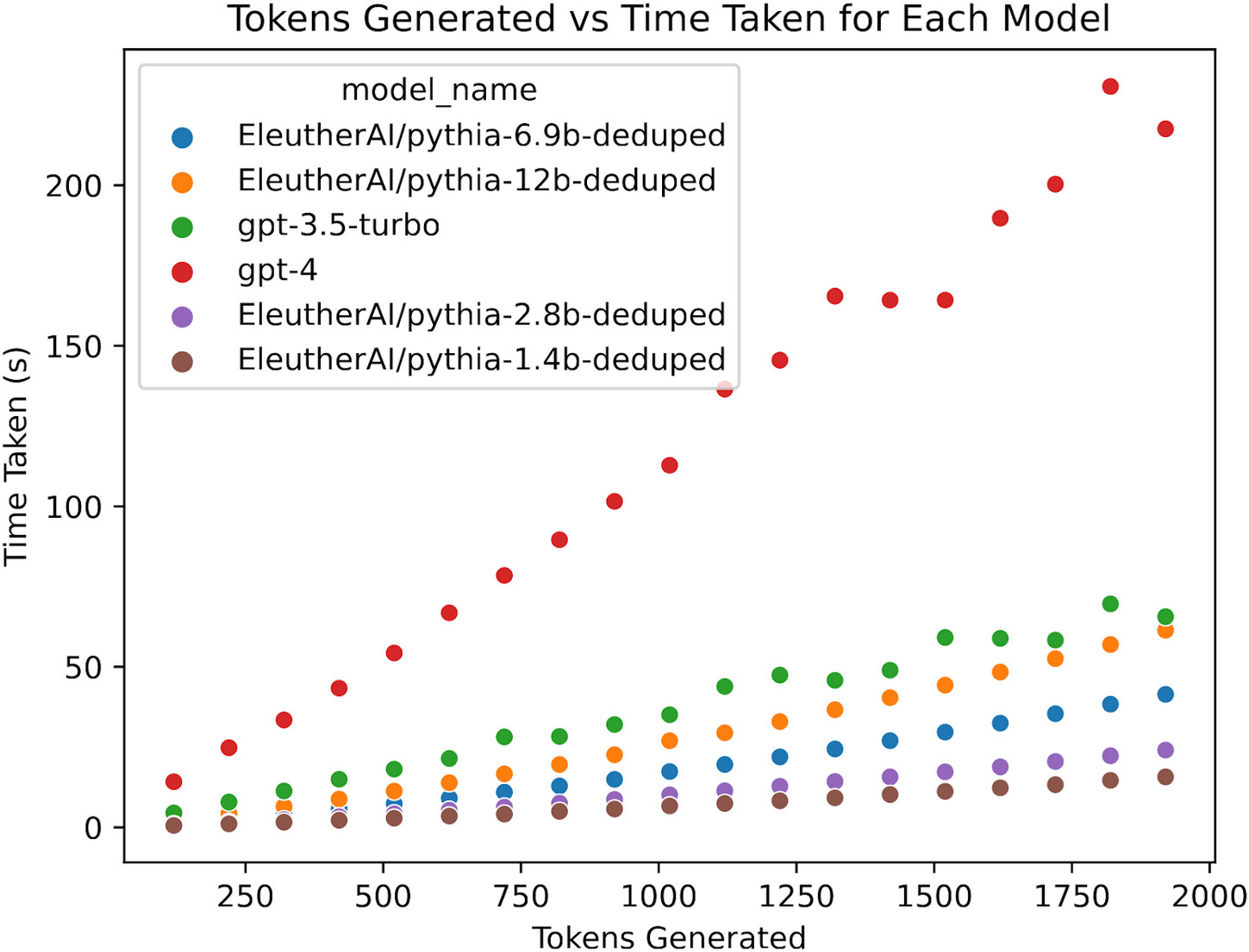
AI leaderboards for evaluating code generation systems are becoming less useful due to a lack of cost considerations. Researchers argue that current benchmarks often overlook the significant expenses associated with complex AI agents that repeatedly invoke language models. Instead, they propose using Pareto curves to visualize the trade-off between accuracy and cost, as simple baseline agents can sometimes achieve comparable results at a fraction of the price. AI
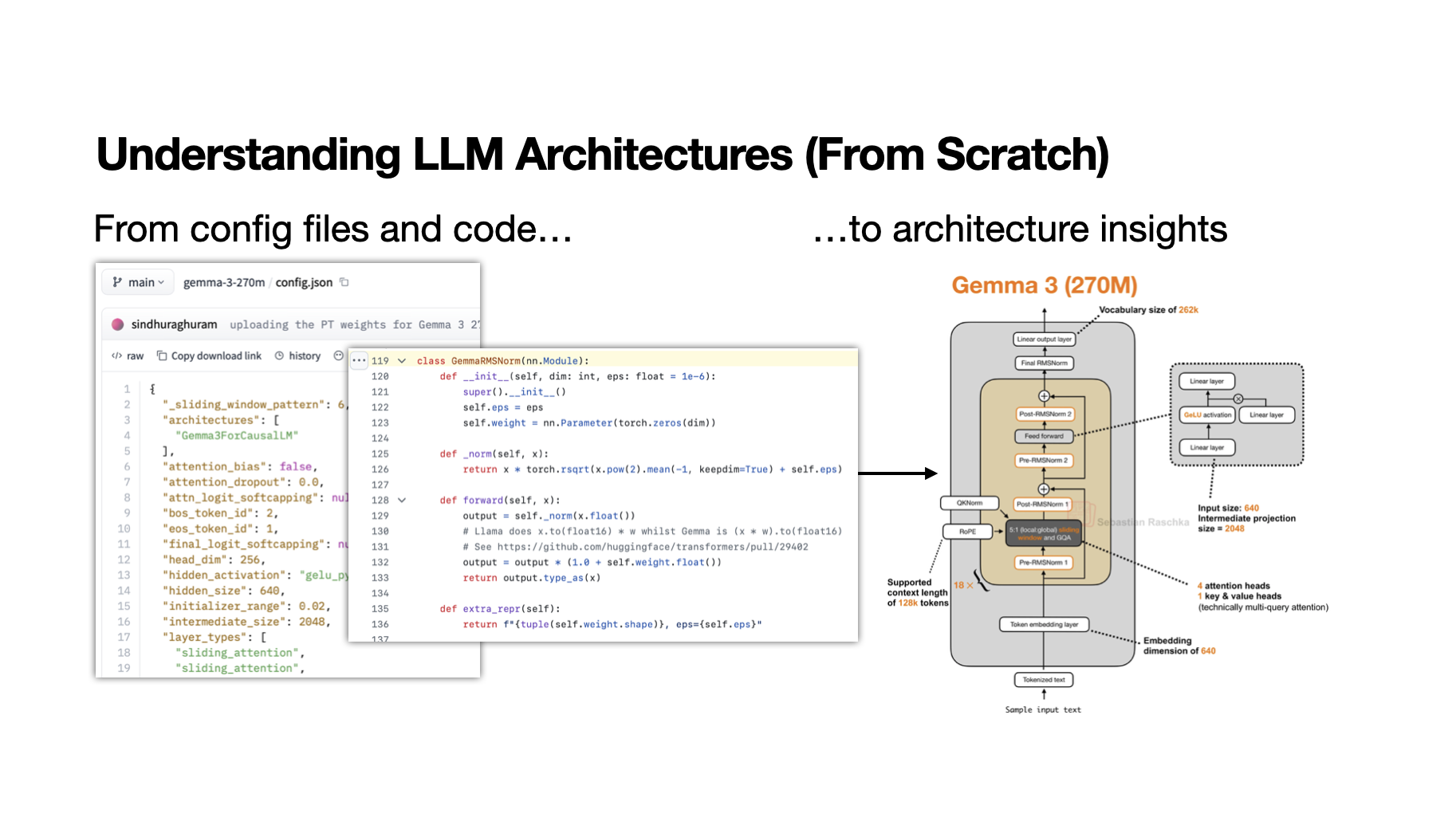








![[GRPO Explained] DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://i3.ytimg.com/vi/bAWV_yrqx4w/hqdefault.jpg)