OpenAI trains LLMs for better instruction hierarchy; new research targets optimization and verification
ByPulseAugur Editorial·
Summary by gemini-2.5-flash-lite
from 30 sources
OpenAI has introduced the IH-Challenge dataset to train large language models to better prioritize instructions from different sources, such as system messages, developers, and users. This training aims to improve safety steerability and robustness against prompt-injection attacks by teaching models to follow a hierarchy where system instructions are most trusted. The dataset is designed to overcome common pitfalls in reinforcement learning for instruction hierarchy, ensuring models can reliably adhere to safety policies even when faced with conflicting user or tool-generated prompts.
AI
IMPACT
Enhances LLMsafety and reliability by improving their ability to follow prioritized instructions, reducing risks from prompt injection and policy violations.
RANK_REASON
OpenAI released a new training dataset and methodology for improving LLM safety and instruction following.
Today's LLMs are susceptible to prompt injections, jailbreaks, and other attacks that allow adversaries to overwrite a model's original instructions with their own malicious prompts.
arXiv:2604.27032v1 Announce Type: cross Abstract: Large Language Models (LLMs) have become an integral part of many real-world workflows. However, LLMs consume a lot of energy, which becomes a large concern in the scale of the demand for these tools. As LLMs become integrated int…
arXiv:2604.26170v1 Announce Type: new Abstract: Adapting large language models (LLMs) to a targeted task efficiently and effectively remains a fundamental challenge. Such adaptation often requires iteratively improving the model toward a targeted task, yet collecting high-quality…
arXiv:2602.15983v2 Announce Type: replace-cross Abstract: Large language models (LLMs) can translate natural language into optimization code, but silent failures pose a critical risk: code that executes and returns solver-feasible solutions may encode semantically incorrect formu…
arXiv:2602.03412v2 Announce Type: replace Abstract: As large language model agents tackle increasingly complex long-horizon tasks, effective post-training becomes critical. Prior work faces fundamental challenges: outcome-only rewards fail to precisely attribute credit to interme…
arXiv:2604.25847v1 Announce Type: cross Abstract: Optimization modeling underpins real-world decision-making in logistics, manufacturing, energy, and public services, but reliably solving such problems from natural-language requirements remains challenging for current large langu…
arXiv cs.CL
TIER_1·Alex Bogdan, Adrian de Valois-Franklin·
arXiv:2604.25634v1 Announce Type: cross Abstract: We report a striking statistical regularity in frontier LLM outputs that enables a CPU-only scoring primitive running at 2.6 microseconds per token, with estimated latency up to 100,000$\times$ (five orders of magnitude) below exi…
Adapting large language models (LLMs) to a targeted task efficiently and effectively remains a fundamental challenge. Such adaptation often requires iteratively improving the model toward a targeted task, yet collecting high-quality human-labeled data to support this process is c…
Optimization modeling underpins real-world decision-making in logistics, manufacturing, energy, and public services, but reliably solving such problems from natural-language requirements remains challenging for current large language models (LLMs). In this paper, we propose \emph…
We report a striking statistical regularity in frontier LLM outputs that enables a CPU-only scoring primitive running at 2.6 microseconds per token, with estimated latency up to 100,000$\times$ (five orders of magnitude) below existing sampling-based detectors. Across six contemp…
arXiv:2604.23626v1 Announce Type: new Abstract: LLM routing has achieved promising results in integrating the strengths of diverse models while balancing efficiency and performance. However, to support more realistic and challenging applications, routing must extend into agentic …
arXiv:2604.23069v1 Announce Type: new Abstract: Large language model (LLM) agents often struggle in long-context interactions. As the agent accumulates more interaction history, context management approaches such as sliding window and prompt compression may omit earlier structure…
arXiv:2604.24715v1 Announce Type: new Abstract: Hybrid sequence models that combine efficient Transformer components with linear sequence modeling blocks are a promising alternative to pure Transformers, but most are still pretrained from scratch and therefore fail to reuse exist…
arXiv:2511.01490v2 Announce Type: replace Abstract: As synthetic data becomes widely used in language model development, understanding its impact on model behavior is crucial. This paper investigates the impact of the diversity of sources of synthetic data on fine-tuned large lan…
arXiv:2509.25414v2 Announce Type: replace-cross Abstract: Large language models are often adapted using parameter-efficient techniques such as Low-Rank Adaptation (LoRA), formulated as $y = W_0x + BAx$, where $W_0$ is the pre-trained parameters and $x$ is the input to the adapted…
arXiv:2604.22783v1 Announce Type: new Abstract: Parameter-Efficient Fine-Tuning (PEFT) has become the standard for adapting large language models (LLMs). In this work we challenge the wide-spread assumption that parameter efficiency equates memory efficiency and on-device adaptab…
arXiv cs.AI
TIER_1·Shiju Wang, Yujie Wang, Ao Sun, Fangcheng Fu, Zijian Zhu, Bin Cui, Xu Han, Kaisheng Ma·
arXiv:2509.21275v4 Announce Type: replace-cross Abstract: Long context training is crucial for LLM's context extension. Existing schemes, such as sequence parallelism, incur substantial communication overhead. Pipeline parallelism (PP) reduces this cost, but its effectiveness hin…
Hybrid sequence models that combine efficient Transformer components with linear sequence modeling blocks are a promising alternative to pure Transformers, but most are still pretrained from scratch and therefore fail to reuse existing Transformer checkpoints. We study upcycling …
arXiv cs.LG
TIER_1·Rajinder Sandhu, Di Mu, Cheng Chang, Md Shahriar Tasjid, Himanshu Rai, Maksims Volkovs, Ga Wu·
arXiv:2604.22722v1 Announce Type: cross Abstract: Dense vector retrieval is the practical backbone of Retrieval- Augmented Generation (RAG), but similarity search can suffer from precision limitations. Conversely, utility-based approaches leveraging LLM re-ranking often achieve s…
arXiv:2601.14287v2 Announce Type: replace Abstract: External memory systems are pivotal for enabling Large Language Model (LLM) agents to maintain persistent knowledge and perform long-horizon decision-making. Existing paradigms typically follow a two-stage process: computational…
Dense vector retrieval is the practical backbone of Retrieval- Augmented Generation (RAG), but similarity search can suffer from precision limitations. Conversely, utility-based approaches leveraging LLM re-ranking often achieve superior performance but are computationally prohib…
Long-term conversational agents need memory systems that capture relationships between events, not merely isolated facts, to support temporal reasoning and multi-hop question answering. Current approaches face a fundamental trade-off: flat memory is efficient but fails to model r…
Long-term conversational agents need memory systems that capture relationships between events, not merely isolated facts, to support temporal reasoning and multi-hop question answering. Current approaches face a fundamental trade-off: flat memory is efficient but fails to model r…
Many approaches to LLM red-teaming leverage an attacker LLM to discover jailbreaks against a target. Several of them task the attacker with identifying effective strategies through trial and error, resulting in a semantically limited range of successes. Another approach discovers…
As Large Language Models (LLMs) become increasingly popular, caching responses so that they can be reused by users with semantically similar queries has become a vital strategy for reducing inference costs and latency. Existing caching frameworks have proposed to decide which que…
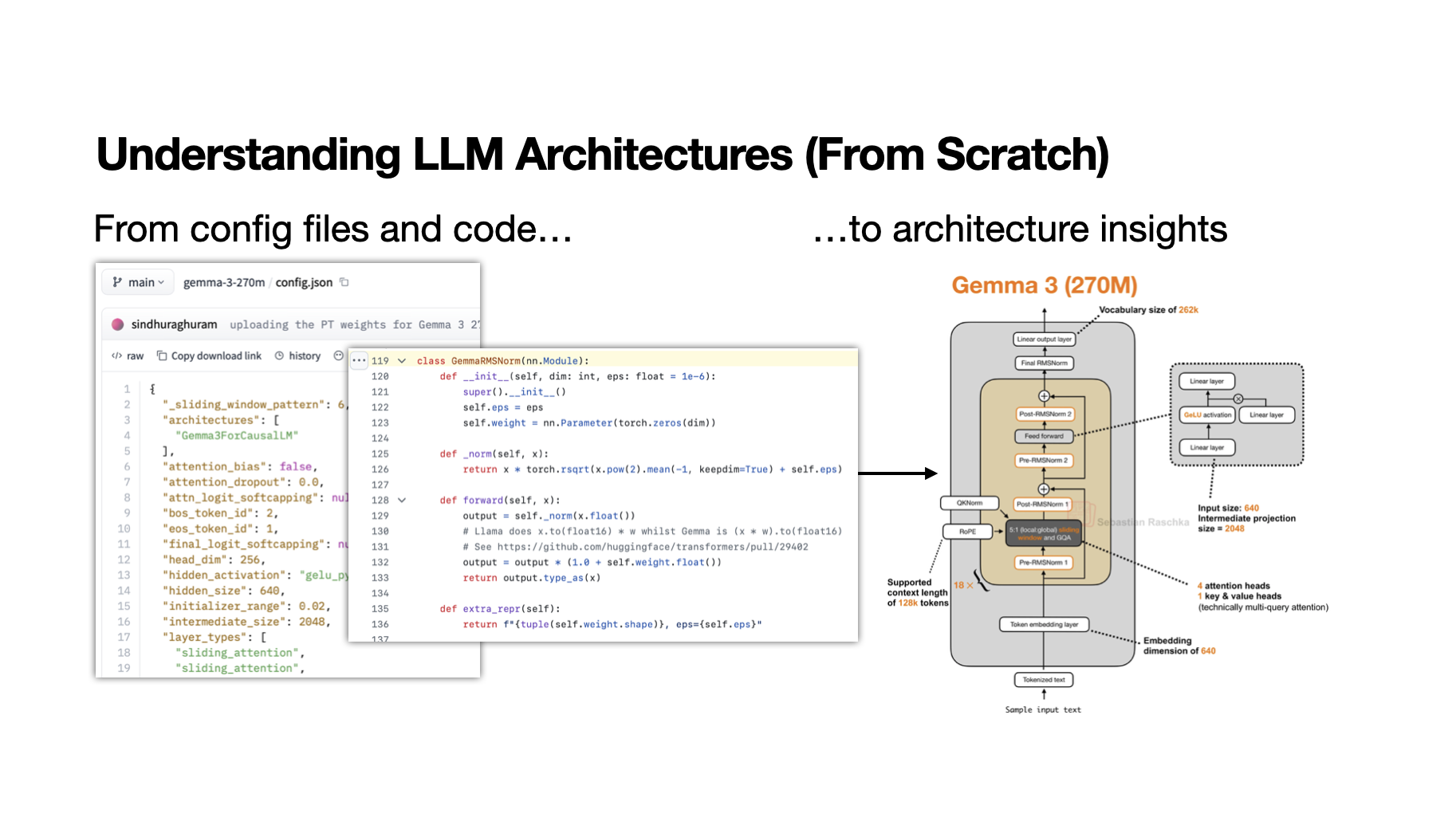
Ahead of AI (Sebastian Raschka)
TIER_1·Sebastian Raschka, PhD·
arXiv:2506.04118v3 Announce Type: replace-cross Abstract: We propose Guided Speculative Inference (GSI), a novel algorithm for efficient reward-guided decoding in large language models. GSI combines soft best-of-$n$ test-time scaling with a reward model $r(x,y)$ and speculative s…
**OpenAI** published a paper introducing the concept of privilege levels for LLMs to address prompt injection vulnerabilities, improving defenses by 20-30%. **Microsoft** released the lightweight **Phi-3-mini** model with 4K and 128K context lengths. **Apple** open-sourced the **…