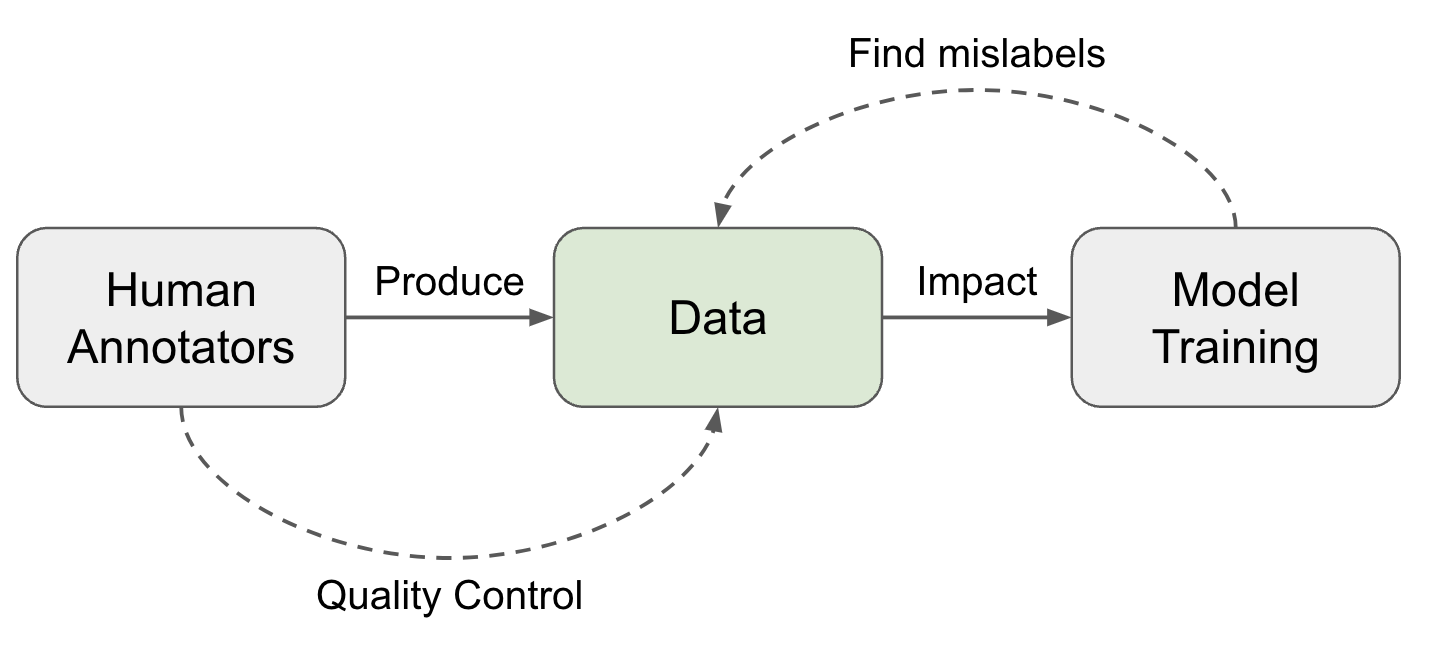
Lilian Weng's latest post explores the critical role of high-quality human data in training deep learning models, emphasizing that data collection is often overlooked in favor of model development. The process involves careful task design, rater selection and training, and data aggregation, with techniques like "wisdom of the crowd" and weighted agreement schemes used to improve reliability. Historical examples, such as an early 20th-century ox-weight guessing contest and studies using Amazon Mechanical Turk for machine translation evaluation, illustrate the effectiveness and challenges of crowdsourced data. AI
RANK_REASON The item is a blog post by a credible researcher discussing existing research and concepts in AI data quality, rather than a new release or significant event.
Read on Lil'Log (Lilian Weng) →
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →