Researchers are exploring advanced diffusion models for video generation, addressing challenges like temporal consistency and data scarcity. New methods focus on improving parameterization, such as the v-prediction technique, and incorporating conditional sampling for tasks like extending video length or filling missing frames. Efforts are also underway to enhance efficiency and controllability through post-training frameworks, hybrid attention mechanisms, and semantic-visual adaptation, aiming for real-time generation and higher quality outputs.
AI
IMPACT
Advances in diffusion models are improving video generation quality, efficiency, and controllability, potentially enabling new applications in content creation and analysis.
RANK_REASON
Multiple arXiv papers and Hugging Face blog posts detail new research and techniques in video generation using diffusion models.
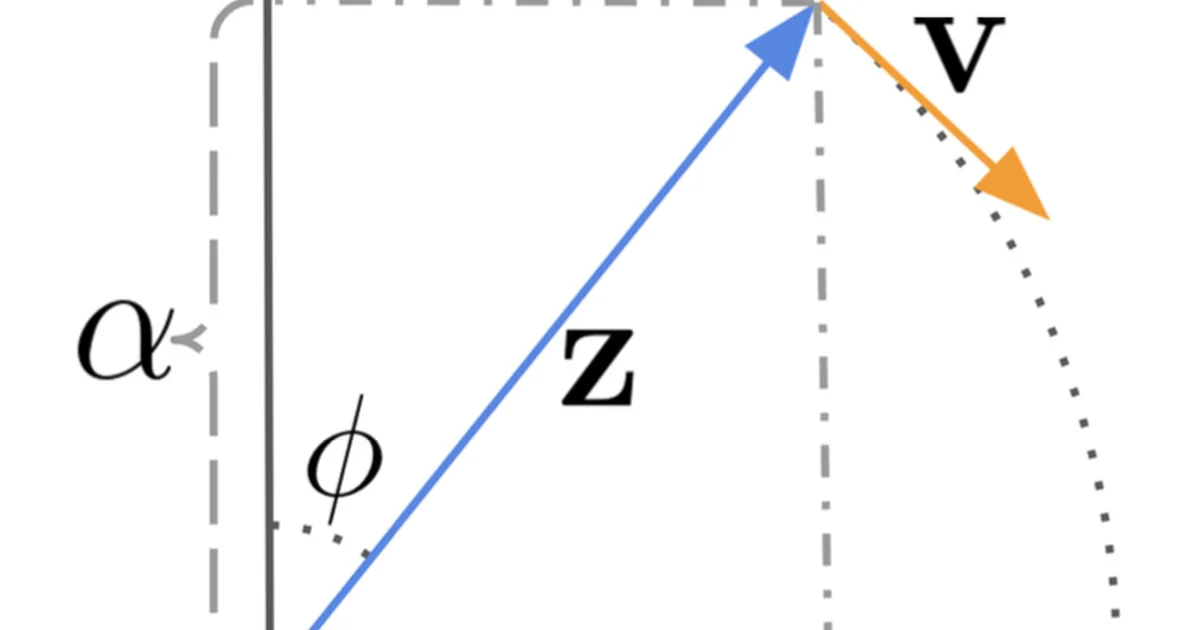
<p><a href="https://lilianweng.github.io/posts/2021-07-11-diffusion-models/">Diffusion models</a> have demonstrated strong results on image synthesis in past years. Now the research community has started working on a harder task—using it for video generation. The task itsel…
arXiv:2605.04830v1 Announce Type: new Abstract: Diffusion models undergo a phase transition in a critical time window during generation dynamics, with two complementary diagnoses of criticality. The symmetry breaking picture views the critical window as when trajectories bifurcat…
Advancing face morphing attack techniques is crucial to anticipate evolving threats and develop robust defensive mechanisms for identity verification systems. This work introduces DCMorph, a dual-stream diffusion-based morphing framework that simultaneously operates at both ident…
Reconstructing 3D human motion and human-object interactions (HOI) from Internet videos is a fundamental step toward building large-scale datasets of human behavior. Existing methods struggle to recover globally consistent 3D motion under dynamic cameras, especially for motion ty…
arXiv cs.CV
TIER_1English(EN)·Dennis Menn, Yuedong Yang, Bokun Wang, Xiwen Wei, Mustafa Munir, Feng Liang, Radu Marculescu, Chenfeng Xu, Diana Marculescu·
arXiv:2603.05811v2 Announce Type: replace Abstract: Current video generation models suffer from high computational latency, making real-time applications prohibitively costly. In this paper, we address this limitation by exploiting the temporal redundancy inherent in video latent…
arXiv:2604.25427v1 Announce Type: new Abstract: While large-scale video diffusion models have demonstrated impressive capabilities in generating high-resolution and semantically rich content, a significant gap remains between their pretraining performance and real-world deploymen…
arXiv cs.CV
TIER_1English(EN)·Ruibin Li, Tao Yang, Fangzhou Ai, Tianhe Wu, Shilei Wen, Bingyue Peng, Lei Zhang·
arXiv:2604.10103v2 Announce Type: replace Abstract: Streaming video generation (SVG) distills a pretrained bidirectional video diffusion model into an autoregressive model equipped with sliding window attention (SWA). However, SWA inevitably loses distant history during long vide…
arXiv:2506.23690v2 Announce Type: replace Abstract: Diffusion-based video motion customization facilitates the acquisition of human motion representations from a few video samples, while achieving arbitrary subjects transfer through precise textual conditioning. Existing approach…
While large-scale video diffusion models have demonstrated impressive capabilities in generating high-resolution and semantically rich content, a significant gap remains between their pretraining performance and real-world deployment requirements due to critical issues such as pr…
arXiv:2604.23858v1 Announce Type: new Abstract: Video generation, while capable of generating realistic videos, is computationally expensive and slow, prohibiting real-time applications. In this paper, we observe that video latents encoded via an autoencoder under the Latent Diff…
arXiv:2604.22808v1 Announce Type: new Abstract: Long-sequence video diffusion transformers hit a quadratic self-attention cost that dominates runtime and memory for very long token sequences. Most efficient attention methods use one approximation everywhere, yet video features ar…
arXiv cs.CV
TIER_1English(EN)·Tristan S. W. Stevens, Ois\'in Nolan, Jean-Luc Robert, Ruud J. G. van Sloun·
arXiv:2509.20886v2 Announce Type: replace Abstract: Video sequences often contain structured noise and background artifacts that obscure dynamic content, posing challenges for accurate analysis and restoration. Robust principal component methods address this by decomposing data i…
Advancing face morphing attack techniques is crucial to anticipate evolving threats and develop robust defensive mechanisms for identity verification systems. This work introduces DCMorph, a dual-stream diffusion-based morphing framework that simultaneously operates at both ident…
We introduce Sparse Forcing, a training-and-inference paradigm for autoregressive video diffusion models that improves long-horizon generation quality while reducing decoding latency. Sparse Forcing is motivated by an empirical observation in autoregressive diffusion rollouts: at…