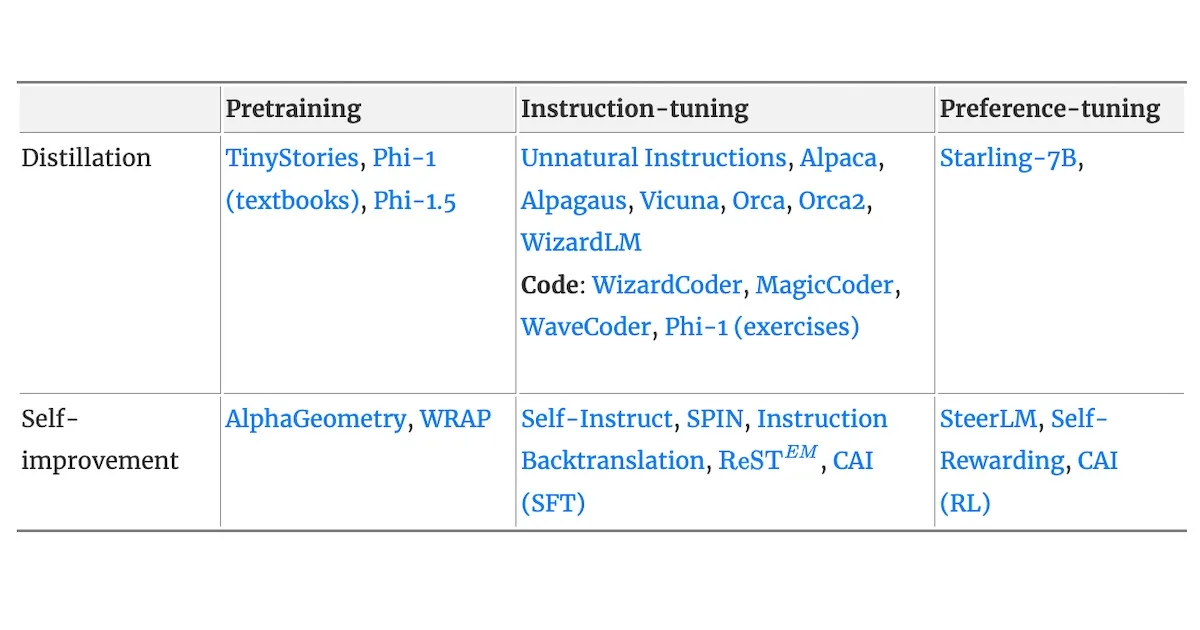
Synthetic data, generated by models or simulations rather than real-world sources, offers a faster and more cost-effective alternative to human annotation for fine-tuning AI models. This approach can lead to improved model performance and generalization while also mitigating privacy and copyright concerns. Two primary methods for generating synthetic data include distillation from a more capable model and self-improvement techniques where a model refines its own output. These methods can be applied to pretraining, instruction-tuning, and preference-tuning to enhance various aspects of a model's capabilities. AI
RANK_REASON The article discusses research papers and techniques for generating synthetic data for AI model fine-tuning.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →