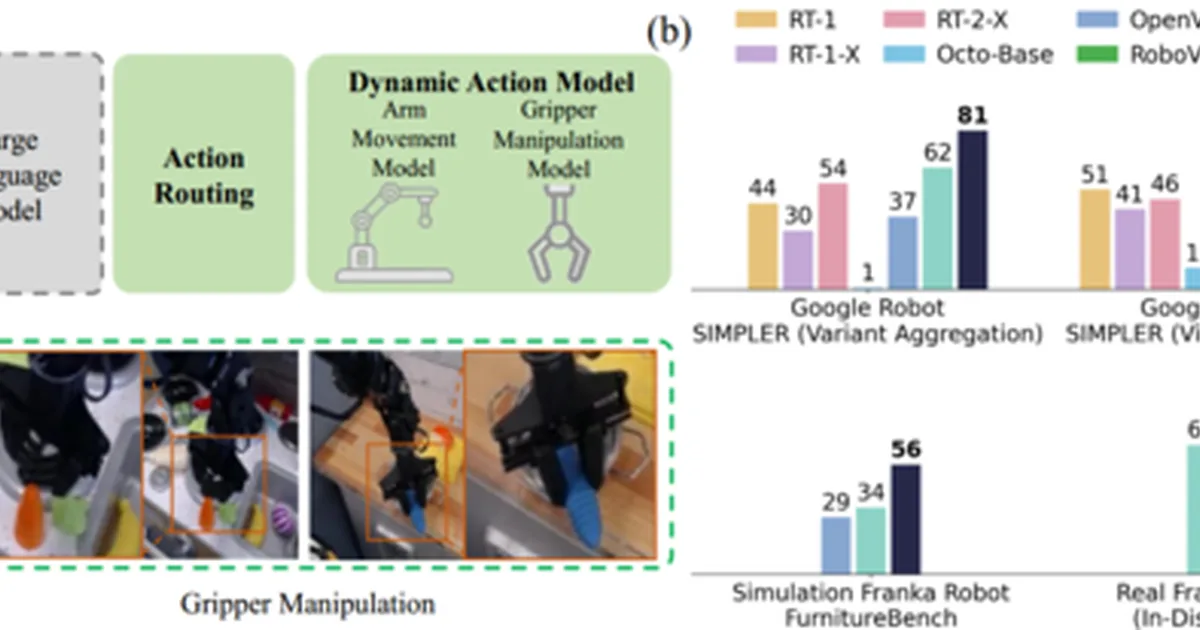
研究人员推出DAM-VLA,这是一种新颖的视觉-语言-动作(VLA)模型,旨在通过解耦手臂运动与抓手动作来增强机器人操控能力。该方法解决了现有模型将单一动作框架用于所有任务的局限性,而这种方法难以应对大规模手臂运动和精确抓手操作的独特需求。DAM-VLA利用双尺度加权机制和动态动作路由来提高效率和准确性,在抓取放置和家具组装任务上取得了最先进的成果。 AI
影响 引入了一种新的VLA架构,提高了机器人操控的准确性和泛化能力,可能加速具身智能的进展。
排序理由 这是一篇详细介绍机器人操控新模型架构的研究论文。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →