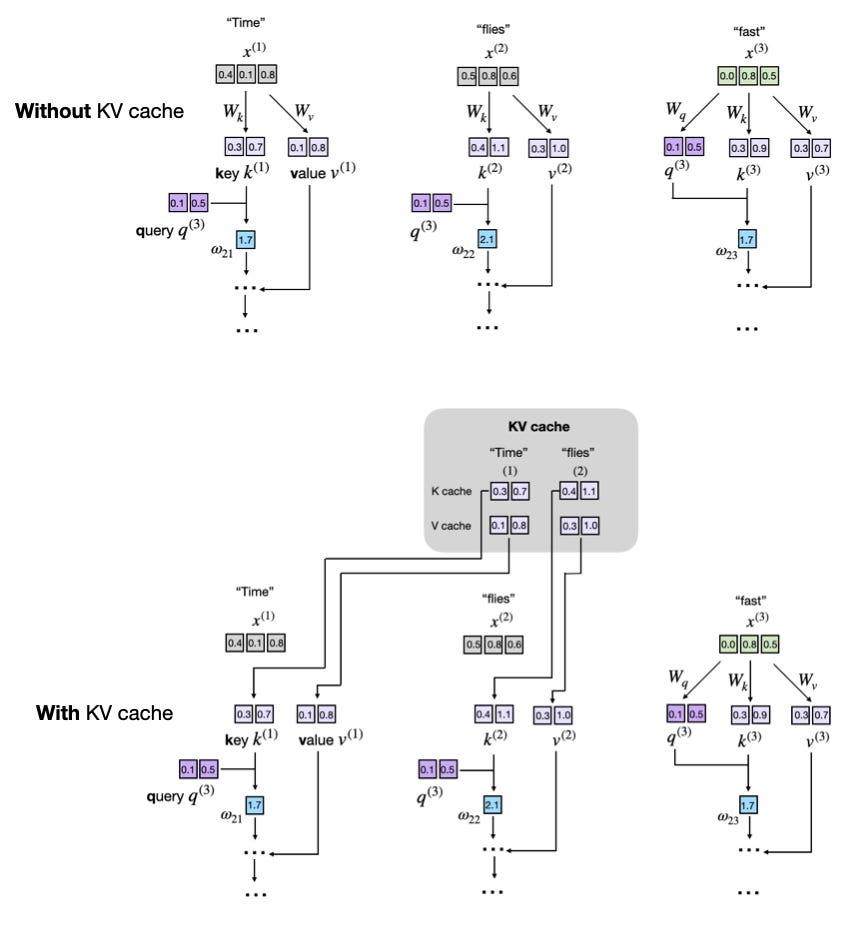
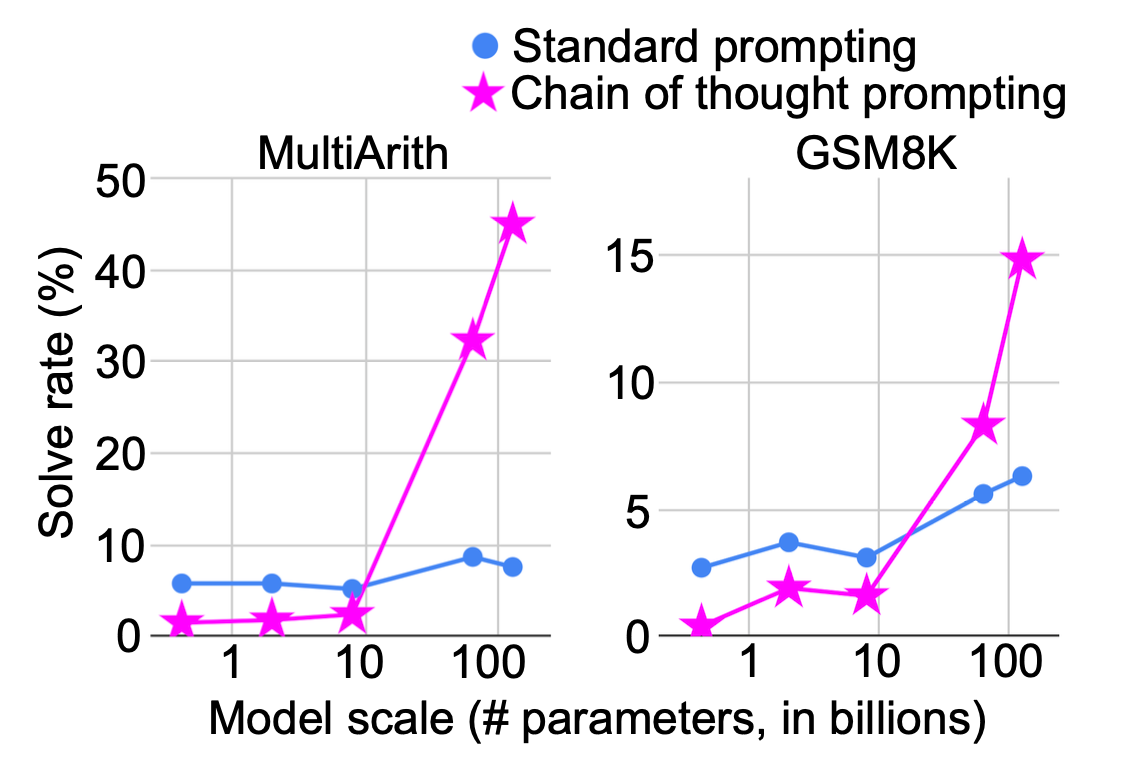
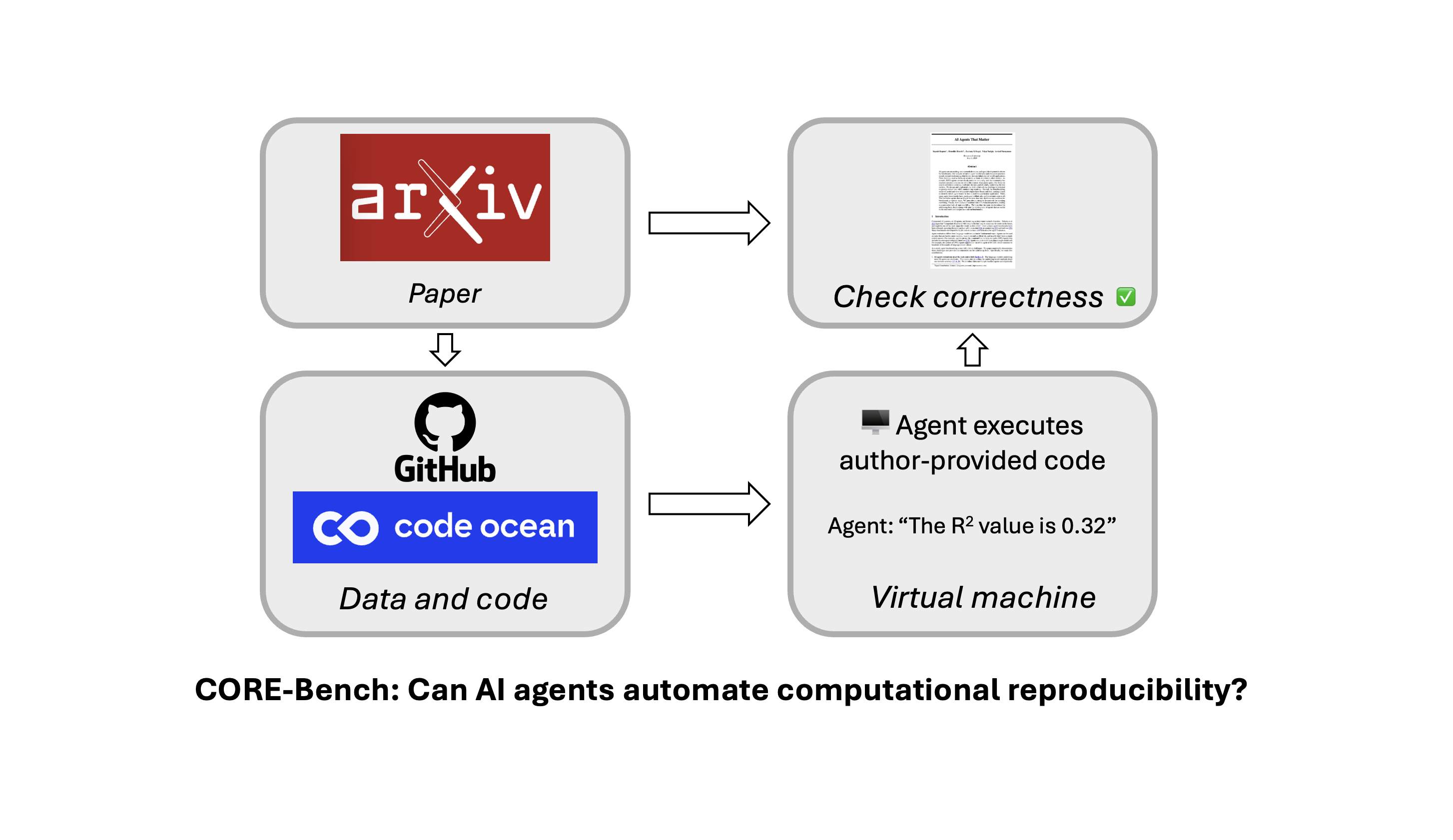
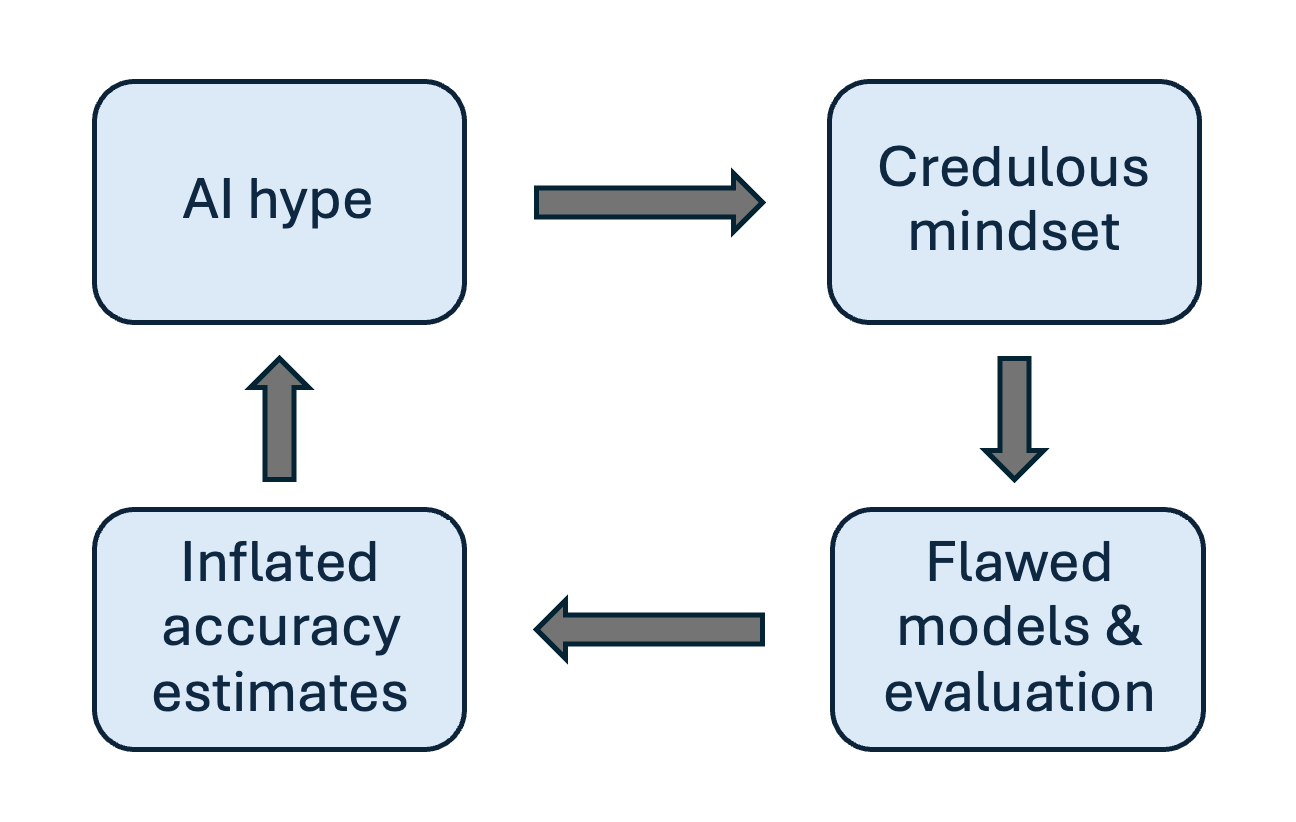
Important machine learning equations
A new guide compiles essential machine learning equations, focusing on their practical application and mathematical foundations. It covers key concepts from information theory, linear algebra, and optimization, including detailed explanations and Python implementations for entropy, cross-entropy, and KL divergence. The resource aims to serve as a handy reference for practitioners, drawing from frequently used formulas and including sections on neural network fundamentals and loss functions. AI

IMPACT Provides a practical reference for core mathematical concepts used in machine learning model development.