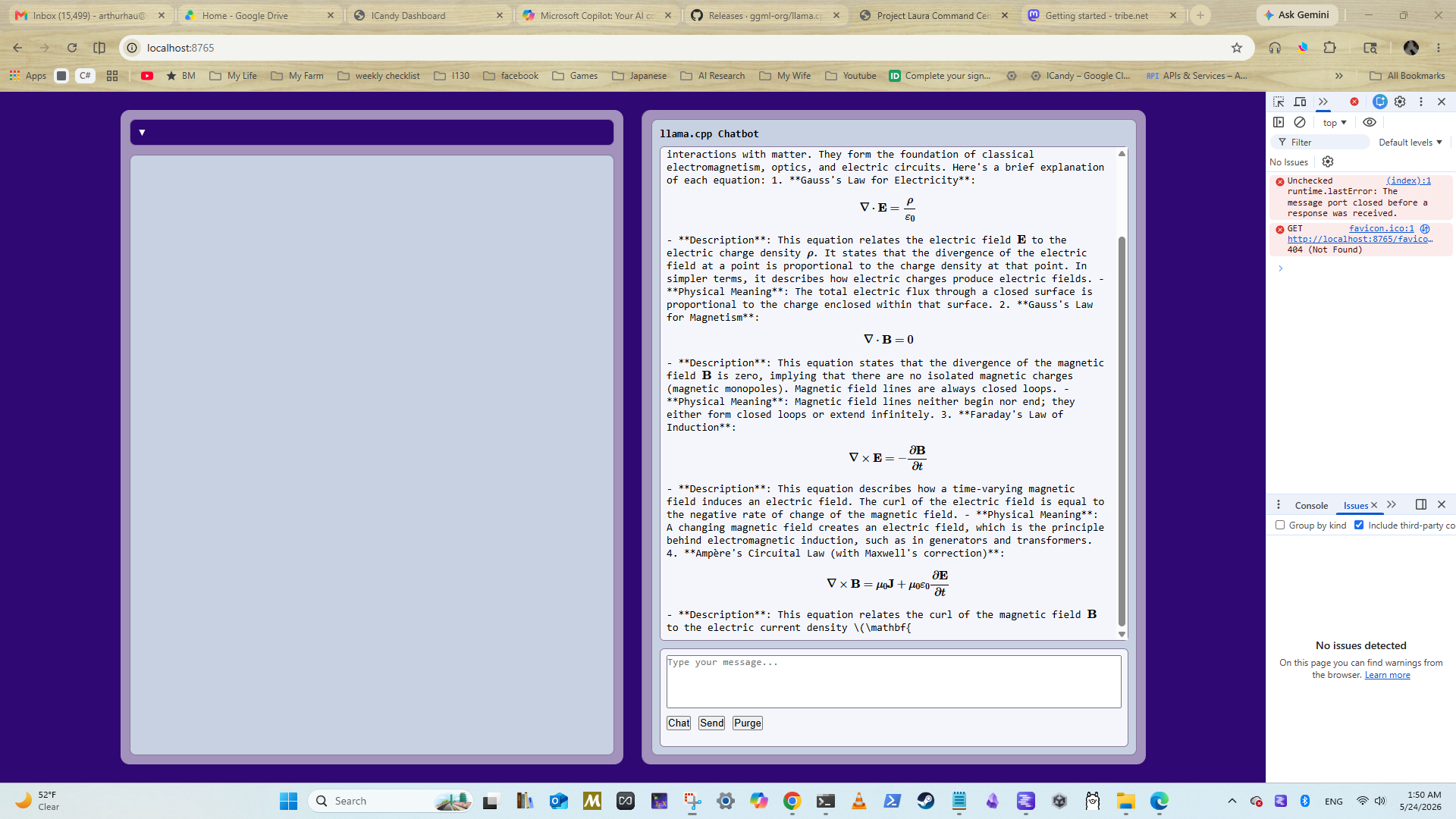
I ran Claude Code on a local LLM for 4 hours — 7M tokens, $0 (would have cost $94)
A developer successfully ran Anthropic's Claude Code locally for four hours, processing 7 million tokens without incurring API costs. This was achieved by routing Claude Code's requests through LiteLLM to a local Qwen3.6-27B-MTP model running on an AMD GPU via llama.cpp. The setup offers benefits such as no rate limits, enhanced privacy, and offline capability, with the developer providing detailed instructions and hardware requirements for replication. AI
IMPACT Enables cost-free, private, and offline use of advanced coding models by leveraging local hardware.