How to Detect GPU Waste in a Kubernetes Cluster
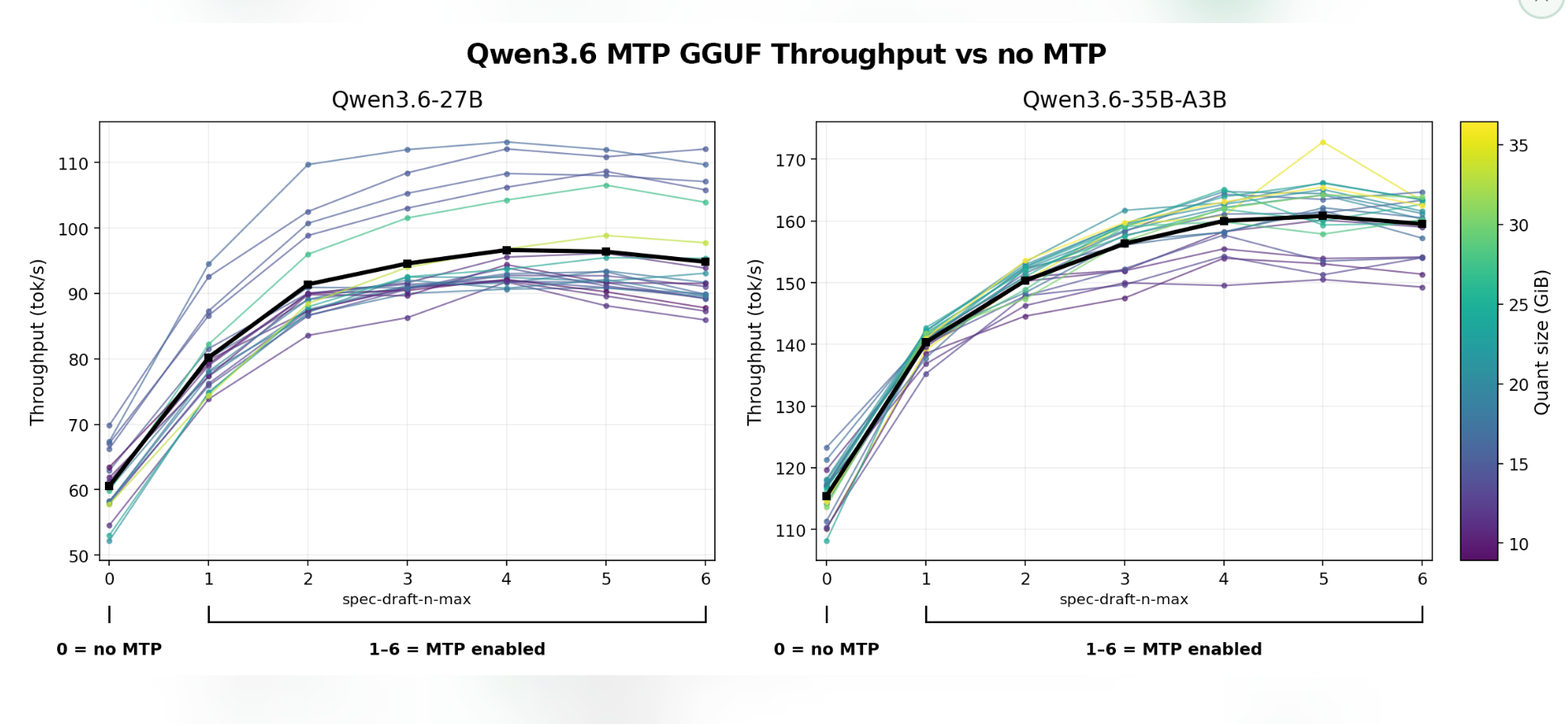
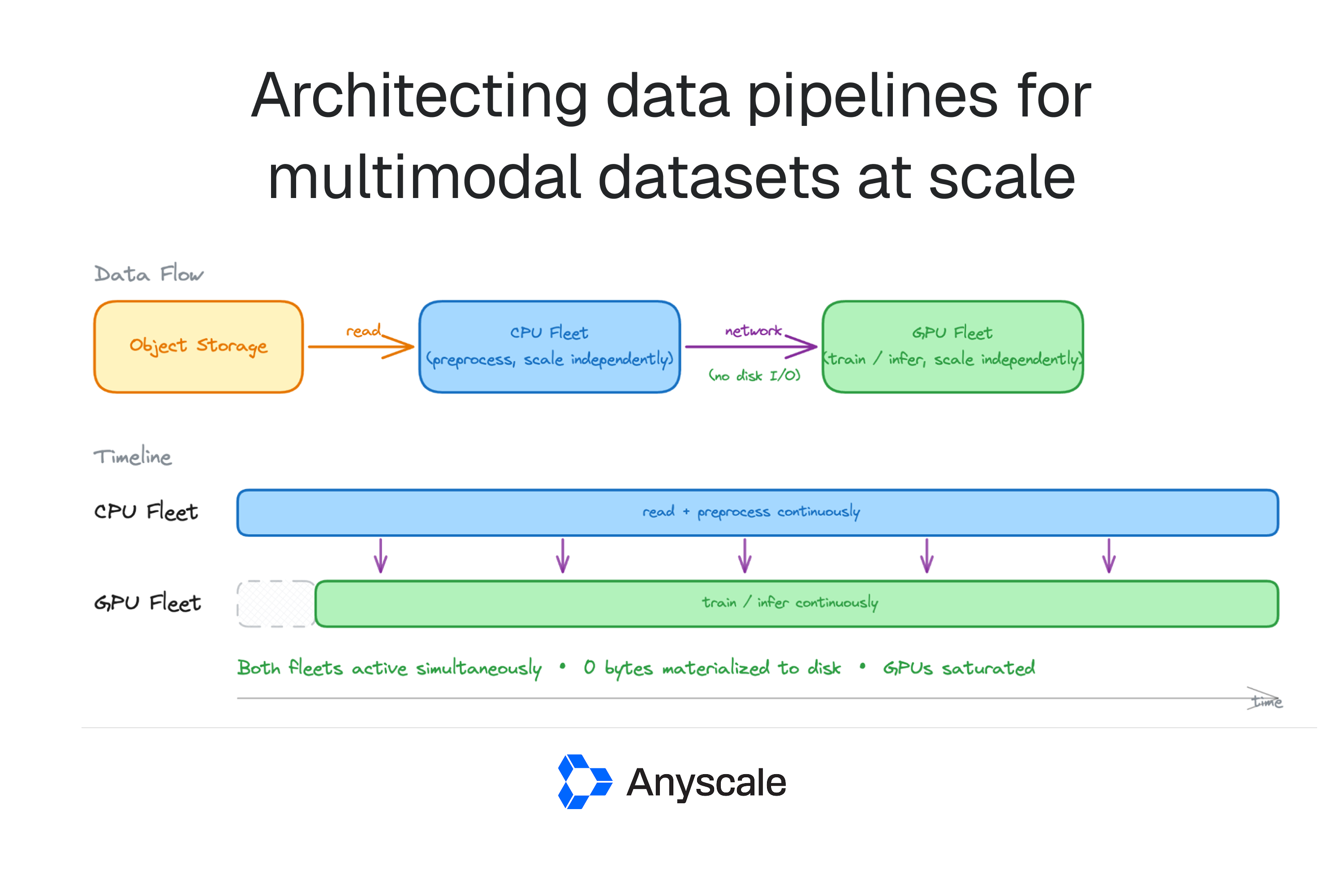
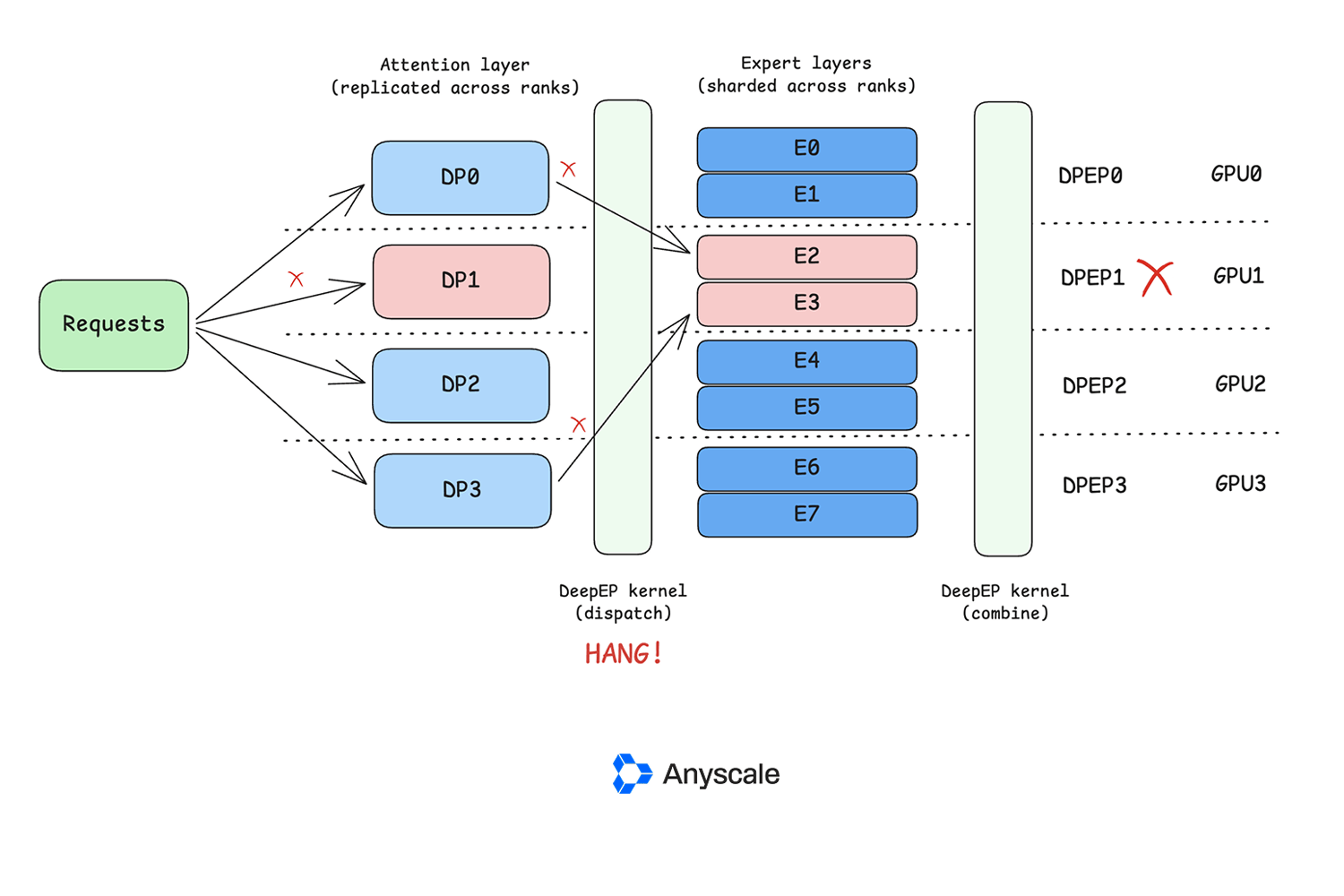
This article discusses how to identify and address GPU waste within Kubernetes clusters, a problem that often goes unnoticed due to seemingly healthy utilization metrics. It highlights that inefficient GPU usage can occur even when overall cluster utilization appears normal. The piece aims to provide methods for detecting these hidden inefficiencies. AI
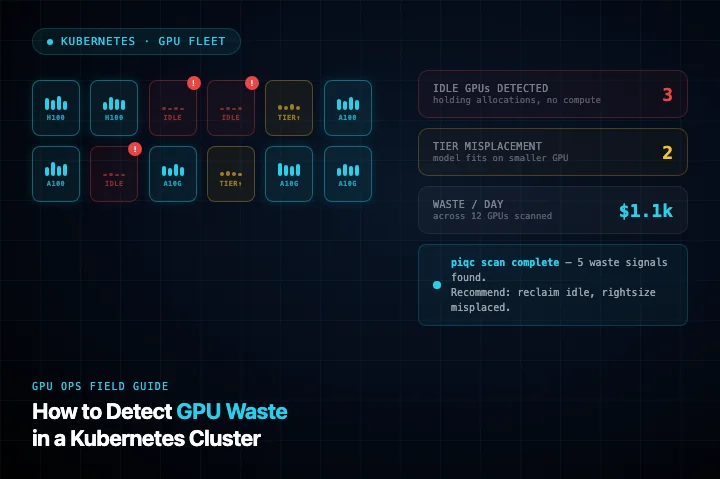
IMPACT Provides guidance for optimizing AI/ML infrastructure costs and efficiency.