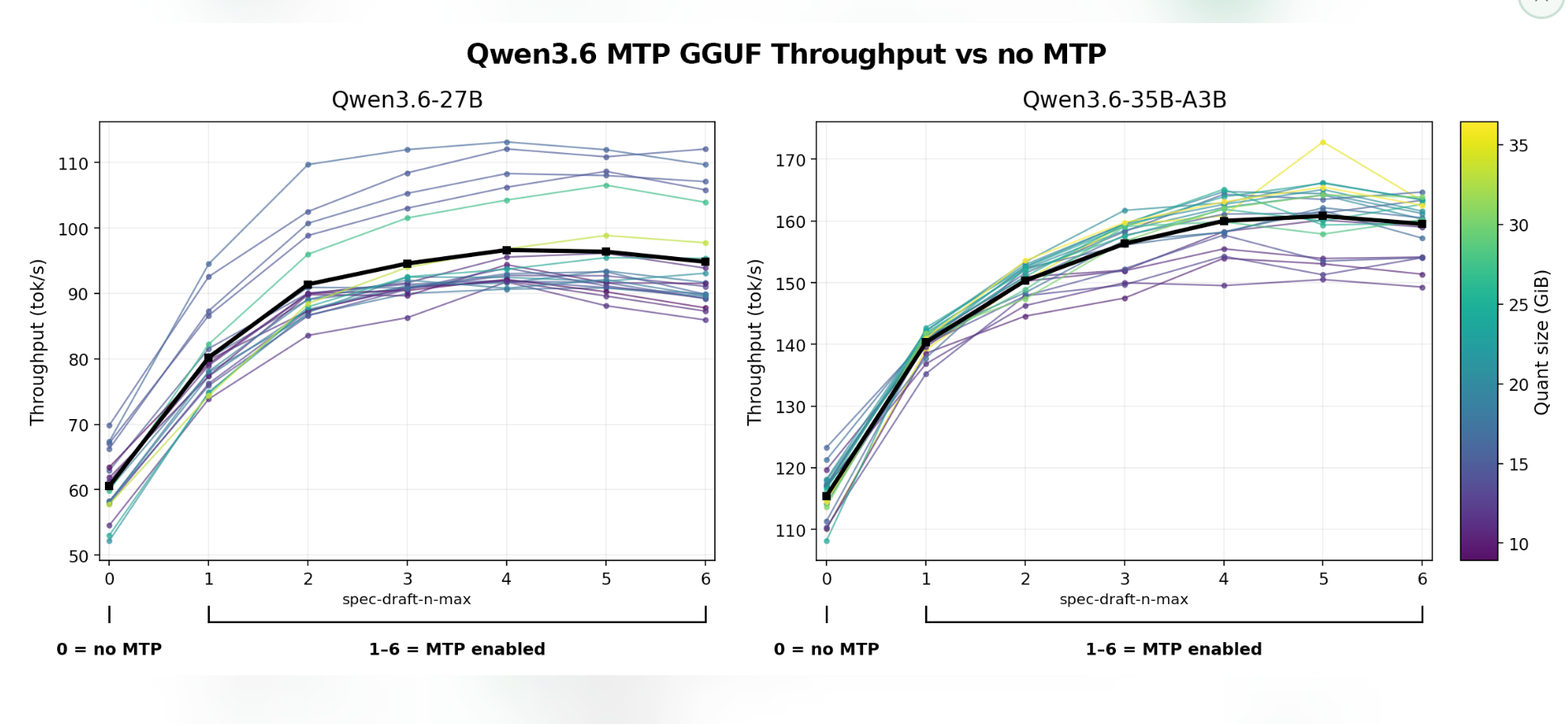
A new method called MTP (Multi-Token Prediction) has been developed to accelerate token generation in AI models. This technique involves predicting multiple future tokens simultaneously and then having the main model verify them in parallel. However, MTP requires a significant increase in VRAM, which can lead to slower generation or reduced context size on GPUs with limited memory. The technique does not appear to reduce model hallucinations. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
IMPACT This technique could speed up AI inference but requires more VRAM, potentially limiting its use on consumer hardware.
RANK_REASON The cluster describes a new technique for AI model inference, which falls under research. [lever_c_demoted from research: ic=1 ai=1.0]