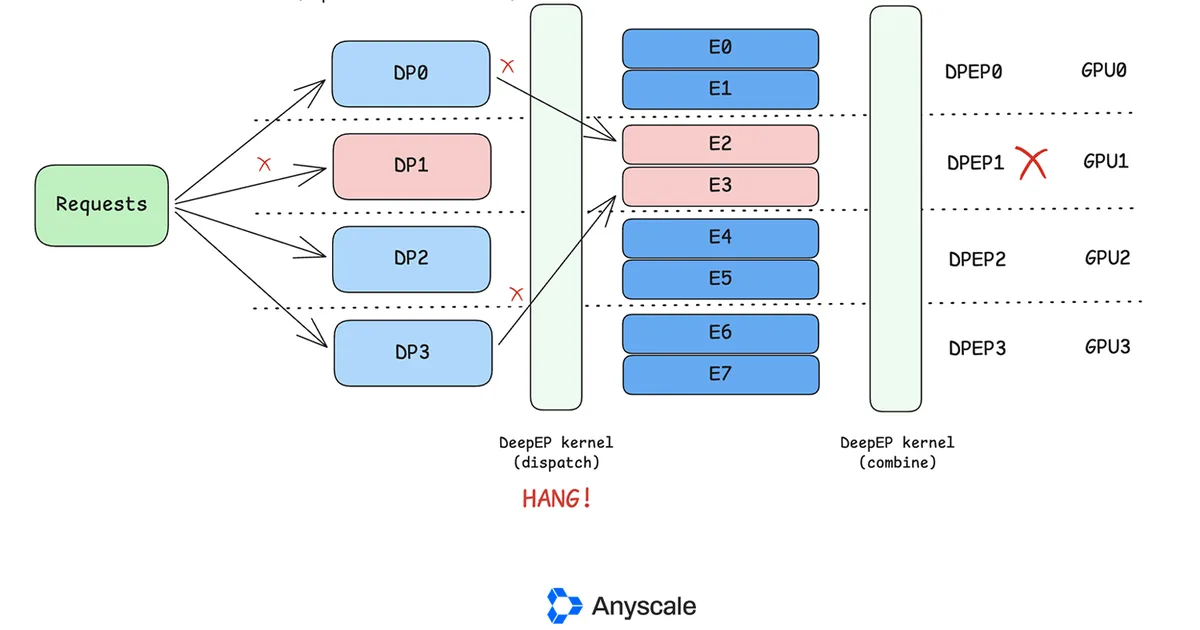
Anyscale has introduced a new fault tolerance feature for its vLLM serving engine, integrated with Ray Serve. This enhancement specifically addresses the challenges of deploying large Mixture-of-Experts (MoE) models, which are sharded across multiple GPUs. The new system can now identify and restart entire groups of GPUs that form a data-parallel (DP) group when a single GPU within that group fails, preventing the entire deployment from becoming unavailable. AI
IMPACT Enhances the reliability and operational efficiency of serving large, complex Mixture-of-Experts models, which are becoming increasingly common.
RANK_REASON This is a product update for an infrastructure tool, not a new model release or core research.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →