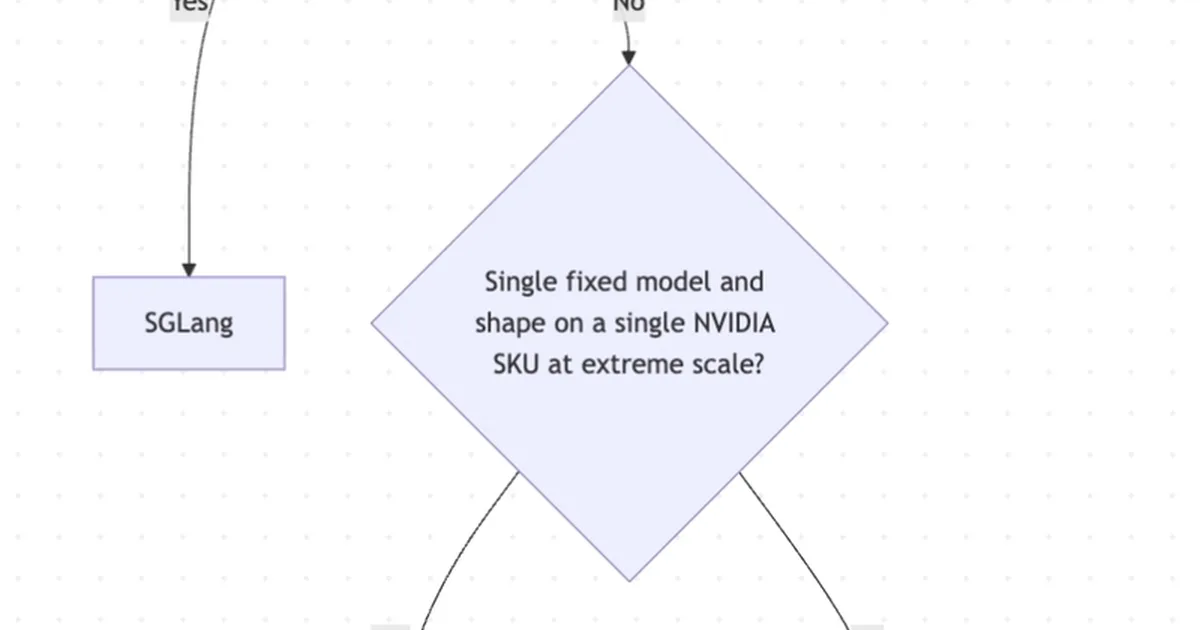
This article provides a guide for optimizing vLLM deployments, focusing on three critical configuration decisions that impact performance and cost. It details how static KV cache allocation can lead to GPU out-of-memory errors and emphasizes the importance of selecting the right serving framework, managing memory budgets for KV cache versus model weights, and configuring batching strategies like chunked prefill and prefix caching. The guide also outlines common failure modes and offers architectural insights for effective vLLM operation. AI
IMPACT Provides crucial operational insights for efficiently deploying and managing large language models using vLLM.
RANK_REASON Article provides operational guidance and configuration details for an existing AI serving framework.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →