阿里巴巴的 Qwen 团队发布了 FlashQLA,这是一套使用 TileLang 开发的新型高性能线性注意力核函数。这些核函数旨在提高大型语言模型中注意力机制的效率。该团队还分享了其 Qwen 模型的基准测试结果,展示了不同配置下的性能。 AI
影响 引入了可提高 LLM 推理速度和效率的优化核函数。
排序理由 发布了新的高性能核函数和现有模型系列的基准测试结果。
AI 生成摘要 · Google Gemini · 来自 3 个来源。 我们如何撰写摘要 →
阿里巴巴的 Qwen 团队发布了 FlashQLA,这是一套使用 TileLang 开发的新型高性能线性注意力核函数。这些核函数旨在提高大型语言模型中注意力机制的效率。该团队还分享了其 Qwen 模型的基准测试结果,展示了不同配置下的性能。 AI
影响 引入了可提高 LLM 推理速度和效率的优化核函数。
排序理由 发布了新的高性能核函数和现有模型系列的基准测试结果。
AI 生成摘要 · Google Gemini · 来自 3 个来源。 我们如何撰写摘要 →
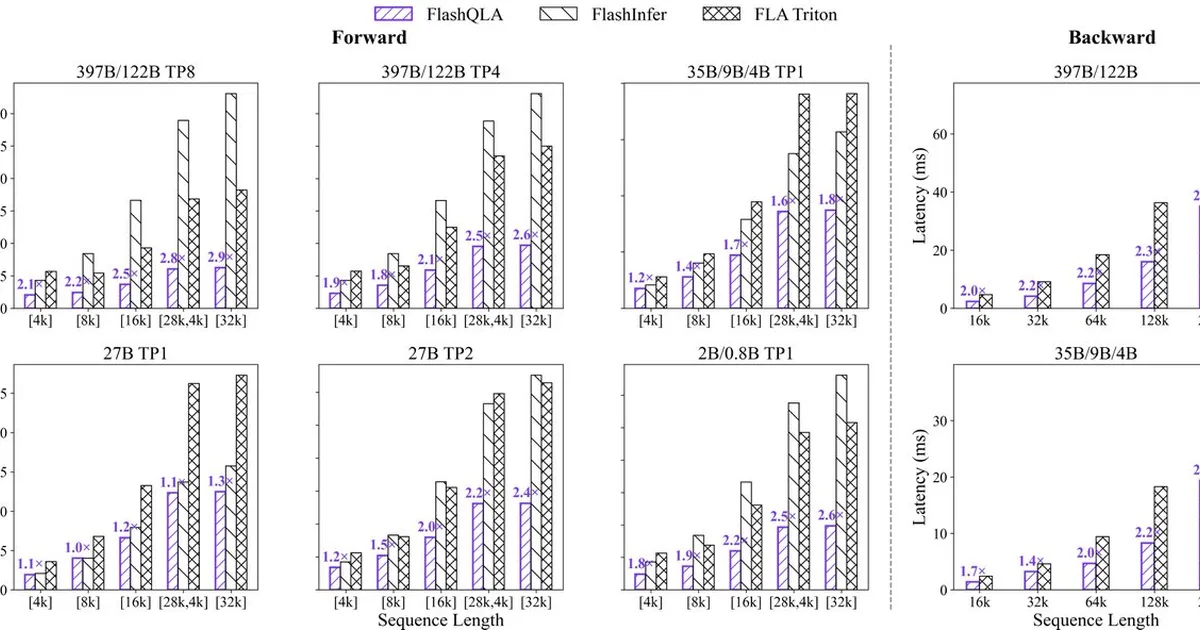
Forward and backward benchmark results across common configurations. https://t.co/IHMCZRw9AW
🚀 Introducing FlashQLA: high-performance linear attention kernels built on TileLang. ⚡ 2–3× forward speedup. 2× backward speedup. 💻 Purpose-built for agentic AI on your personal devices. 💡Key insights: 1. Gate-driven automatic intra-card CP. 2. Hardware-friendly algebraic https…
🚀 Introducing FlashQLA: high-performance linear attention kernels built on TileLang. ⚡ 2–3× forward speedup. 2× backward speedup. 💻 Purpose-built for agentic AI on your personal devices. 💡Key insights: 1. Gate-driven automatic intra-card CP. 2. Hardware-friendly algebraic https…