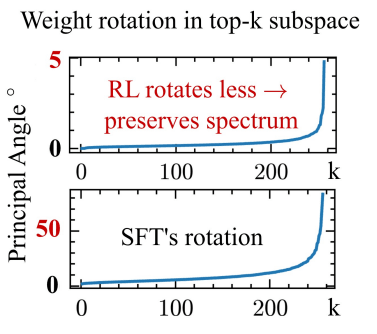
新研究表明,人类反馈强化学习 (RLHF) 以不同于预训练或监督微调的方式更新 LLM 权重。这些 RLHF 更新更稀疏,并且倾向于较少地旋转模型的principal subspaces,表明它们在修改模型行为方面存在定性差异。研究结果表明,RLHF 可能主要激发现有能力,而不是创造新能力,并且与监督微调相比,对不相关任务的性能下降可能更少。 AI
影响 表明 RLHF 可能主要激发现有能力,而不是创造新能力,影响模型的训练和评估方式。
排序理由 该集群由一篇博客文章组成,该文章总结并分析了关于 LLM 中人类反馈强化学习 (RLHF) 的几篇学术论文。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →