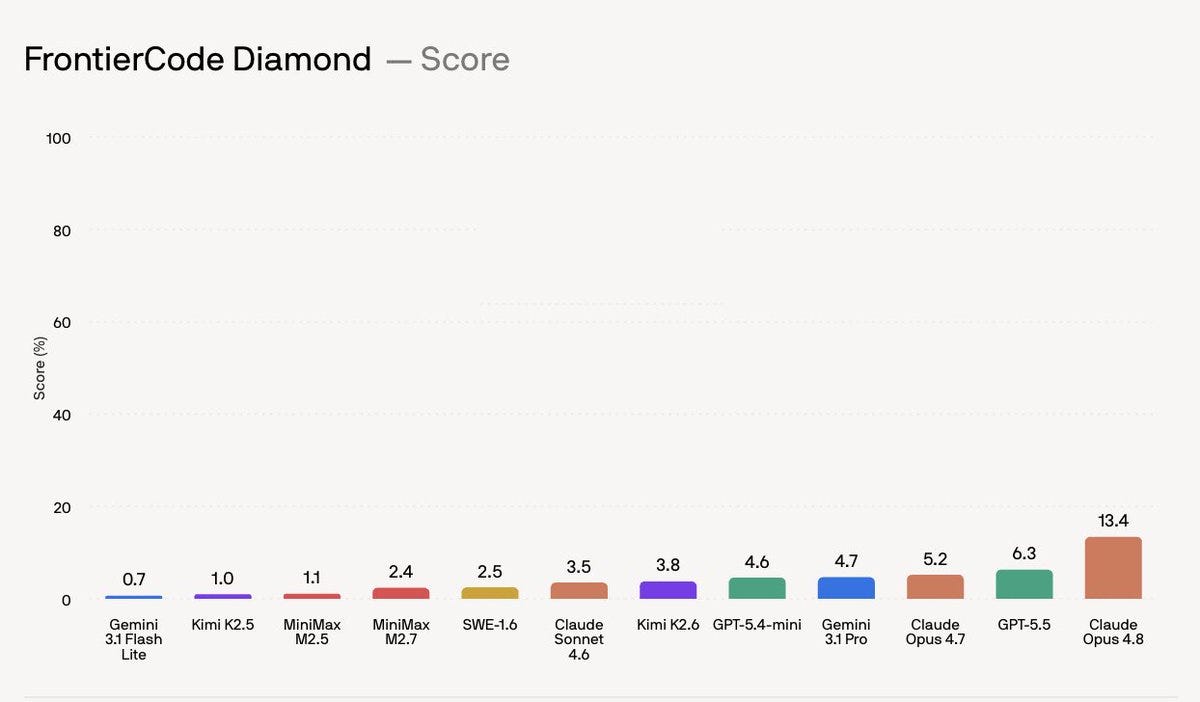
Cognition 发布了 FrontierCode,这是一个旨在评估 AI 生成代码的质量和可合并性的新基准。与之前侧重于通过单元测试的基准不同,FrontierCode 评估回归安全性、简洁性和可维护性等因素,任务完成需要超过 40 小时。早期结果表明,即使是 Opus 4.8 等顶级模型在最难的级别上也得分较低,这表明当前 AI 在生成生产就绪代码方面的能力不如之前所认为的那样先进。 AI
影响 凸显了当前 AI 在生成生产就绪代码方面的能力局限性,表明需要更稳健的评估方法。
排序理由 该集群描述了一个新的基准及其初步发现,这是一个研究里程碑。
AI 生成摘要 · Google Gemini · 来自 2 个来源。 我们如何撰写摘要 →