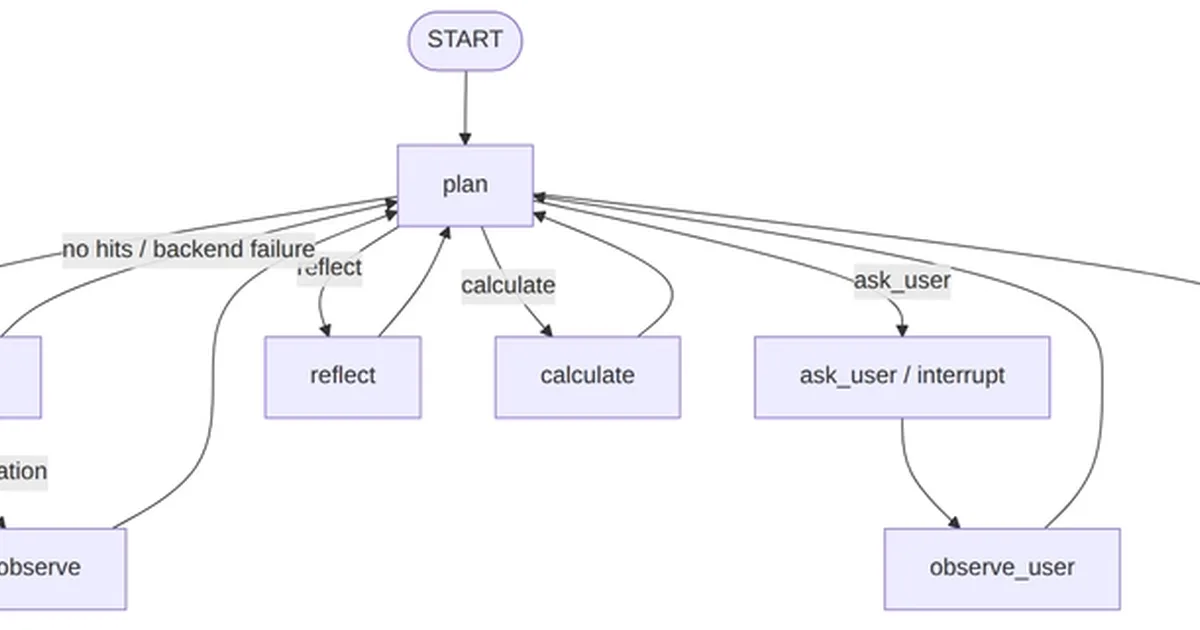
一项实验评估了十一个大型语言模型重构LangGraph代理中复杂“神节点”的能力。模型被要求提出解决方案来梳理该节点的逻辑,然后互相评估彼此的提案。作者采用了三种不同的方法来确定哪些模型作为代码生成器和评估者最值得信赖。 AI
影响 这项研究探讨了LLM在代码理解和重构方面的能力,可能为未来AI辅助编码工具的发展提供信息。
排序理由 该项目详细介绍了一项比较LLM在特定任务(代码重构和评估)上性能的实验,该任务属于研究范畴。[lever_c_demoted from research: ic=1 ai=1.0]
- DeepSeek-4-pro
- Gemini-3.1-pro
- GLM-5.1
- GPT-5.4
- GPT-5.5
- Kimi-2.6
- LangGraph
- MiMo-2.5-pro
- Opus-4.7
- Qwen-3.6-plus
- Qwen-3.7-max
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →