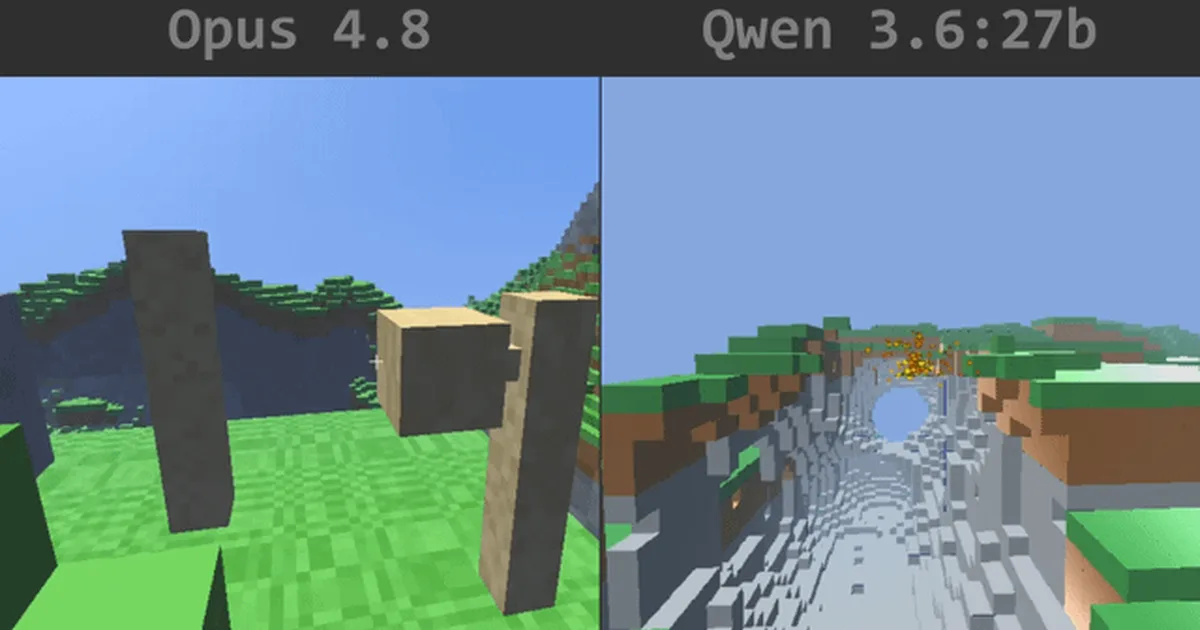
一项近期实验将 Anthropic 的 Opus 4.8 与本地运行的 Qwen3.6-27B 模型进行了比较,任务是让两者都生成体素引擎的 C 语言代码。Opus 4.8 成功创建了一个功能性的体素世界,具有正确的地形和碰撞,展示了对体素物理学的清晰理解。相比之下,Qwen3.6-27B 模型尽管处理了原始 C 代码和手动内存管理,但生成了一个损坏但仍可运行的世界。这凸显了小型、本地可运行模型能力的显著进步,即使它们在整体质量上落后于前沿模型。 AI
影响 展示了本地模型在复杂编码任务中能力快速提升,缩小了与前沿模型的差距。
排序理由 这是用户对两个模型的比较,并非直接发布或官方基准测试。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →