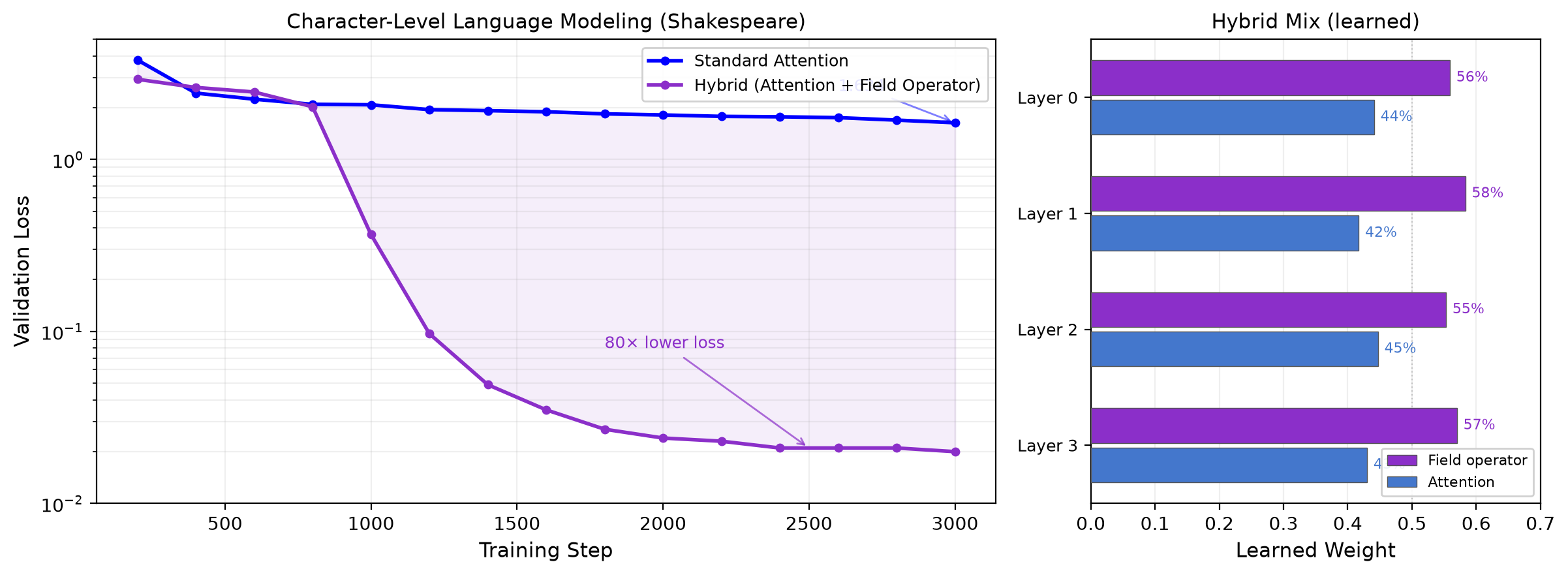
一种名为 BeamGPT 的新型算子已被开发出来,它通过识别标准注意力机制所遗漏的序列结构,显著改善了语言模型的学习曲线。该算子集成到类 nanoGPT 模型中后,在各层实现了约 45% 的注意力与 55% 的 BeamGPT 混合比例。BeamGPT 在序列长度上是线性的,与标准注意力的二次复杂度相比具有显著优势,在长上下文情况下可节省约 2.3 倍的计算资源。用 BeamGPT 替换标准的 MLP 层可将训练损失降低 73 倍,参数量减少近 4 倍,但该算子的确切表示形式将谨慎发布。 AI
影响 引入了一种更高效的语言模型算子,有望降低训练成本并提高性能。
排序理由 博客文章中描述了一种新颖的语言模型算子,而非来自主要实验室的正式论文或发布。[lever_c_research 降级:ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →