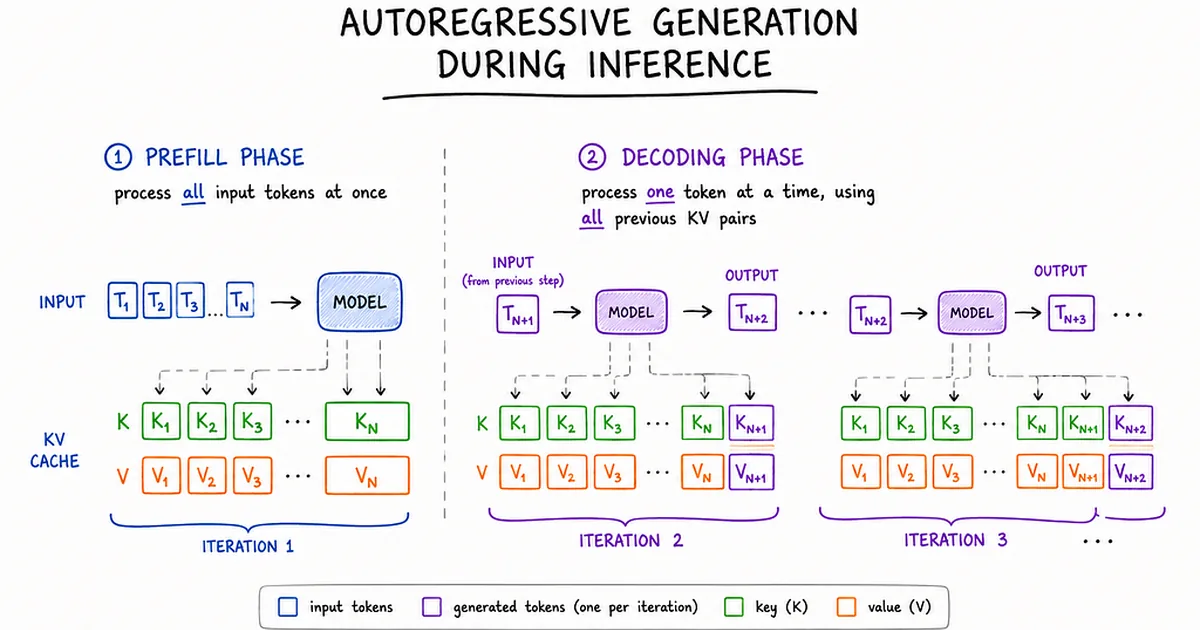
现代大型语言模型推理面临系统挑战,其中初始 token 生成(预填充)和后续 token 生成(解码)需要截然不同的硬件行为。预填充阶段是计算密集型的,同时处理所有输入 token;而解码阶段是内存密集型的,需要为生成的每个 token 从 HBM 中频繁加载模型权重。这种根本差异造成了冲突,因为优化一个阶段通常会损害另一个阶段的性能,从而导致权衡,通过缓慢的首次 token 时间(TTFT)或迟缓的输出 token 时间(TPOT)影响用户体验。 AI
影响 优化 LLM 推理的预填充和解码阶段对于改善用户体验和降低计算成本至关重要。
排序理由 该条目讨论了 LLM 推理中与硬件利用率和性能优化相关的技术挑战,属于研究范畴。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →