RAG Is A Hack - with Jerry Liu from LlamaIndex
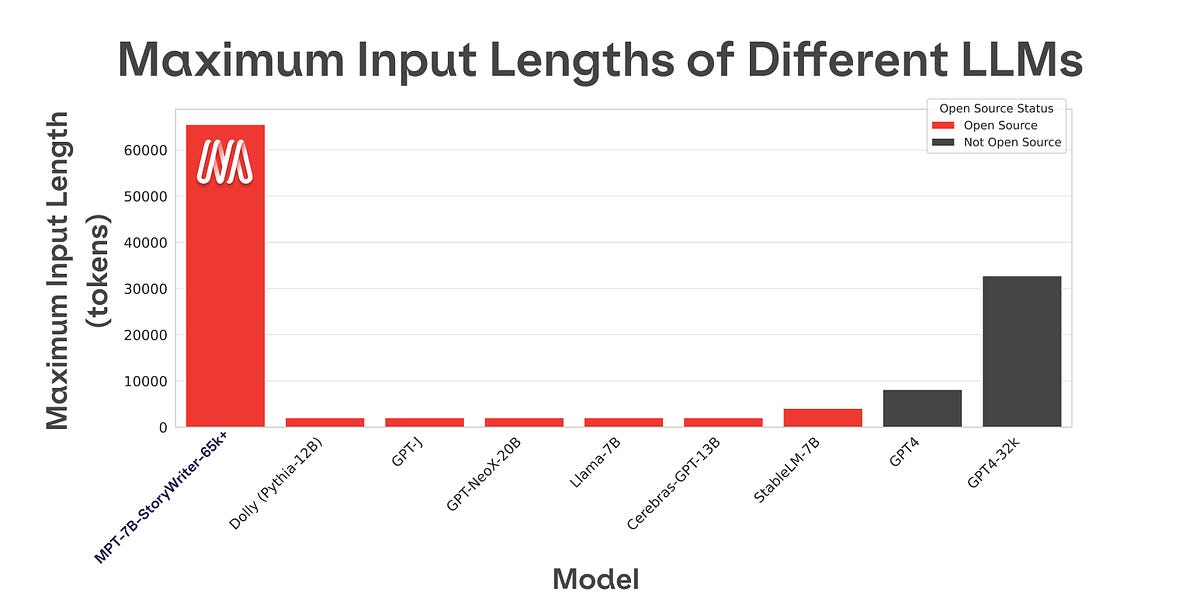
LlamaIndex, a tool for integrating large datasets with language models, has seen significant growth since its inception in October 2022. Initially developed as "GPT Tree Index" to address limitations with GPT-3's context window, it has become a leading platform for Retrieval Augmented Generation (RAG). The project's open-source community expanded rapidly after the release of LlamaHub, which provides over 200 data connectors for various sources. AI