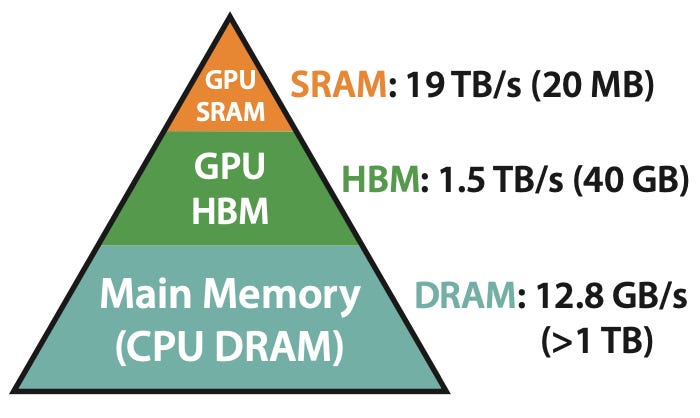
Tri Dao, a recent Stanford PhD graduate and key author of the FlashAttention paper, discussed the advancements in attention mechanisms for Transformers on the Latent Space podcast. FlashAttention, first released in May 2022, significantly speeds up Transformer models by optimizing memory usage and reducing read/write overhead between GPU memory types. The newly released FlashAttention-2 further enhances these capabilities, making it a standard component in many open-source large language models. AI
RANK_REASON Discussion of a research paper and its subsequent iteration, FlashAttention-2, which has broad adoption in open-source LLMs.
Read on Latent Space Podcast →
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →