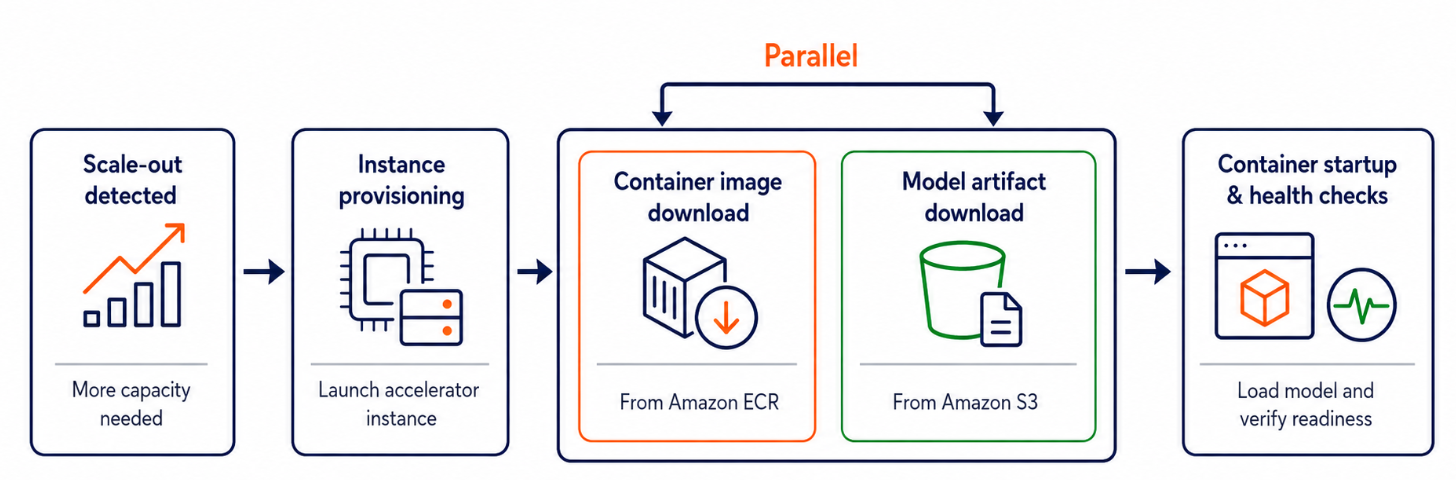
Amazon SageMaker AI 推出了容器缓存功能,以加速推理过程中的模型扩展。此新功能通过消除新实例预配时下载容器镜像的时间,将生成式 AI 模型的端到端延迟最多降低 51%。对于大型模型和复杂工作负载,此改进尤为显著,在测试案例中将启动时间从 525 秒缩短至 258 秒。 AI
影响 通过降低推理延迟,加速生成式 AI 模型的部署和扩展。
排序理由 这是对现有 AI 平台的产品更新,而非新的模型发布或核心研究。
在 AWS Machine Learning Blog 阅读 →
- Amazon CloudWatch
- Amazon Elastic Compute Cloud
- Amazon Elastic Container Registry
- Amazon S3
- Amazon SageMaker AI
- NVIDIA Triton
- SageMaker Large Model Inference
- vLLM
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →