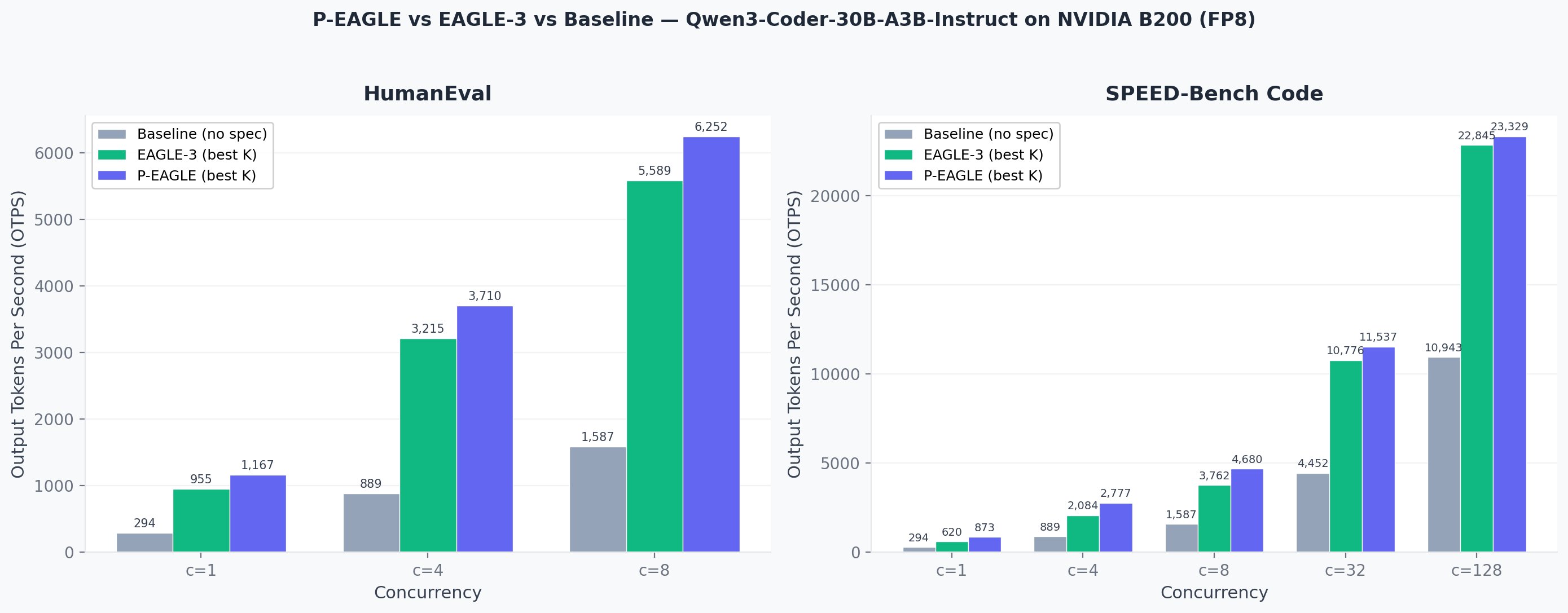
AWS 开发了 Parallel-EAGLE (P-EAGLE),一种新颖的方法,可对大型语言模型实现推测解码并行化,显著提高推理吞吐量。与之前顺序生成草稿 token 的 EAGLE 框架不同,P-EAGLE 在单次前向传播中同时预测所有推测 token,减少了延迟开销。这项创新现已集成到 Amazon SageMaker JumpStart 中,与在流行的基础模型上使用 EAGLE-3 相比,每秒输出 token 的速度提高了 1.69 倍。 AI
影响 加速 LLM 推理速度,从而能够更有效地部署生成式 AI 应用。
排序理由 这是优化 LLM 推理的新方法,已集成到云平台中,但并非新的前沿模型发布或核心研究论文。
在 AWS Machine Learning Blog 阅读 →
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →