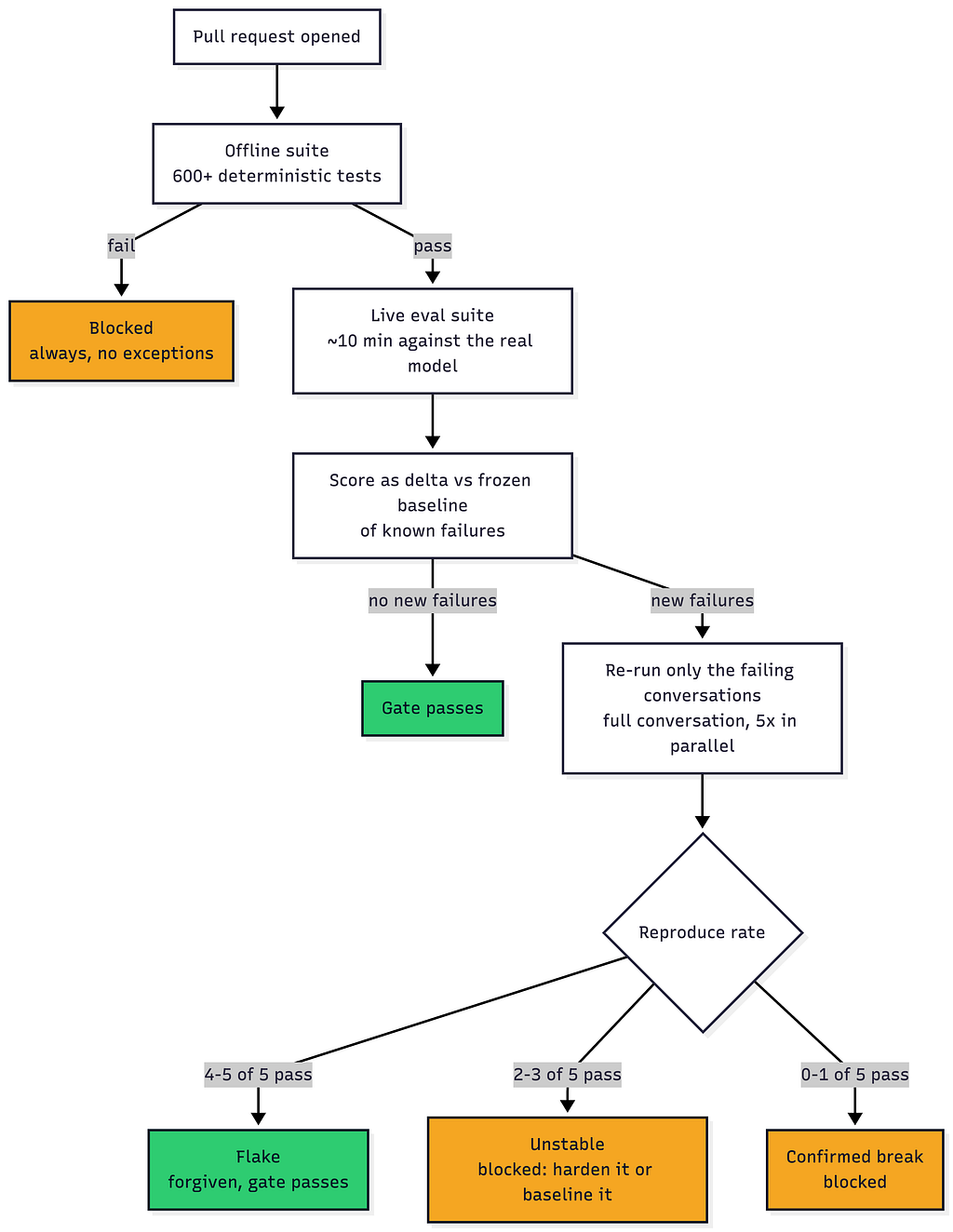
由于大型语言模型(LLM)的非确定性,评估它们面临挑战,尤其是在受监管的产品中。一个常见的问题是,自动化评估仪表板可能显示基于易于验证的指标(如工具选择)的绿色分数,而用户却遇到错误的答案。本文详细介绍了一种改进LLM评估的策略,重点关注呈现给用户的实际答案,并采用多层级通过标准,包括用于安全性的排除子字符串、用于事实准确性的必需子字符串,以及用于忠实于源数据的LLM裁判。 AI
排序理由 文章讨论了LLM评估的最佳实践,而非特定的发布或事件。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →