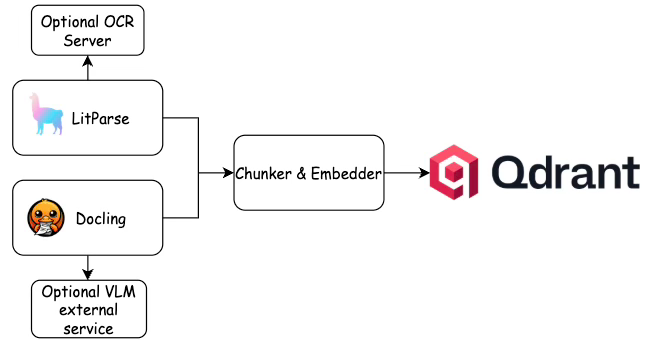
本文评估了两个开源文档解析器,来自LlamaIndex的LitParse和来自IBM Research的Docling,它们在为检索增强生成(RAG)管道准备文档方面的有效性。评估重点考察了一个包含复杂表格和代码块的340页技术教科书,突出了文档解析在RAG系统性能中至关重要但常被忽视的作用。目标是提供关于这些解析器在摄入Qdrant等向量数据库之前如何处理困难文档结构的客观性能数据。 AI
影响 准确的文档解析对于有效的RAG系统至关重要,影响检索质量和LLM性能。
排序理由 文章对用于特定AI任务(RAG管道预处理)的开源工具进行了评估,属于研究与开发范畴。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →