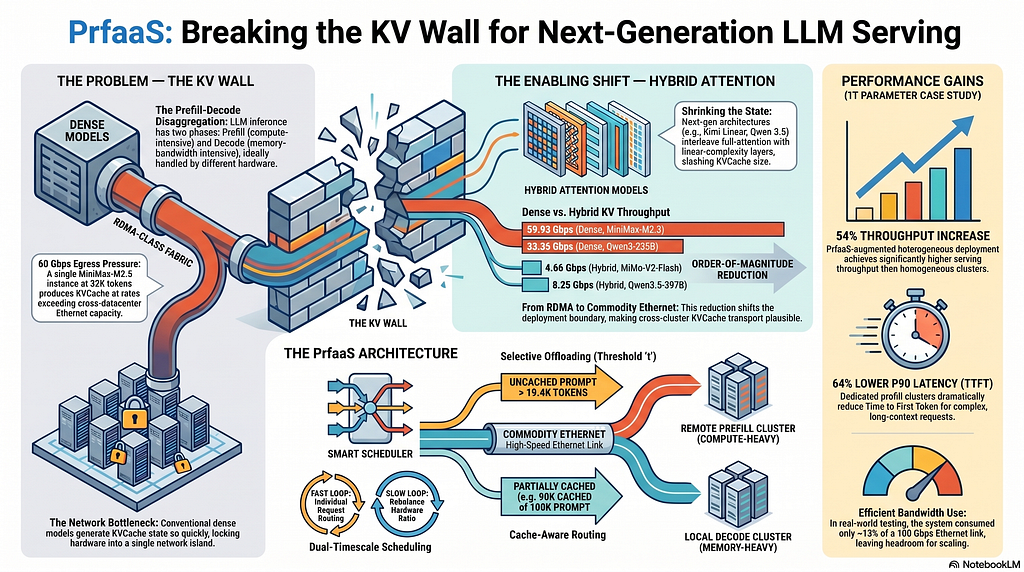
来自Moonshot AI和清华大学的一篇新论文提出了一种克服大型语言模型服务中“KV壁垒”的方法。该方法称为“Prefill-as-a-Service”,通过使用混合注意力模型减小KV缓存,并实施智能路由仅卸载必要的请求,从而实现跨数据中心推理。这对于计算密集型和带宽优化型芯片未共置的异构硬件设置至关重要。 AI
影响 能够更有效地跨分布式硬件提供LLM服务,可能降低推理成本和延迟。
排序理由 该集群讨论了一篇详细介绍LLM服务新技术方法的学术论文。[lever_c_demoted from research: ic=1 ai=1.0]
- Groq
- hybrid-attention models
- KV cache
- Moonshot AI
- NVIDIA
- Prefill-as-a-Service
- Transformer
- Tsinghua University
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →