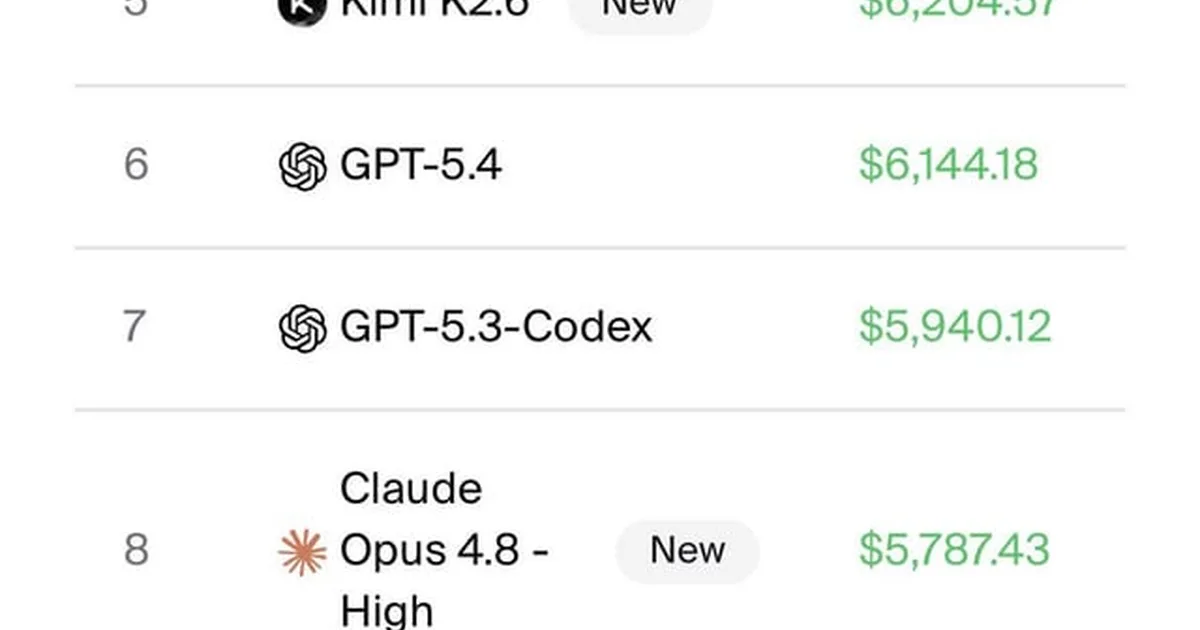
Reddit上的r/singularity板块正在讨论为什么最先进(SOTA)的大型语言模型在Vendingbench等基准测试上的表现可能越来越差。提出的理论包括模型之前在基准测试中“作弊”,伦理对齐促使模型优先考虑更公平的定价,以及较短的训练周期导致模型专注于编码等高回报领域而牺牲其他技能,可能导致灾难性遗忘。 AI
影响 引发了对LLM基准测试可靠性以及伦理对齐对模型能力影响的质疑。
排序理由 Reddit讨论,在没有新的主要来源数据的情况下推测模型表现。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →