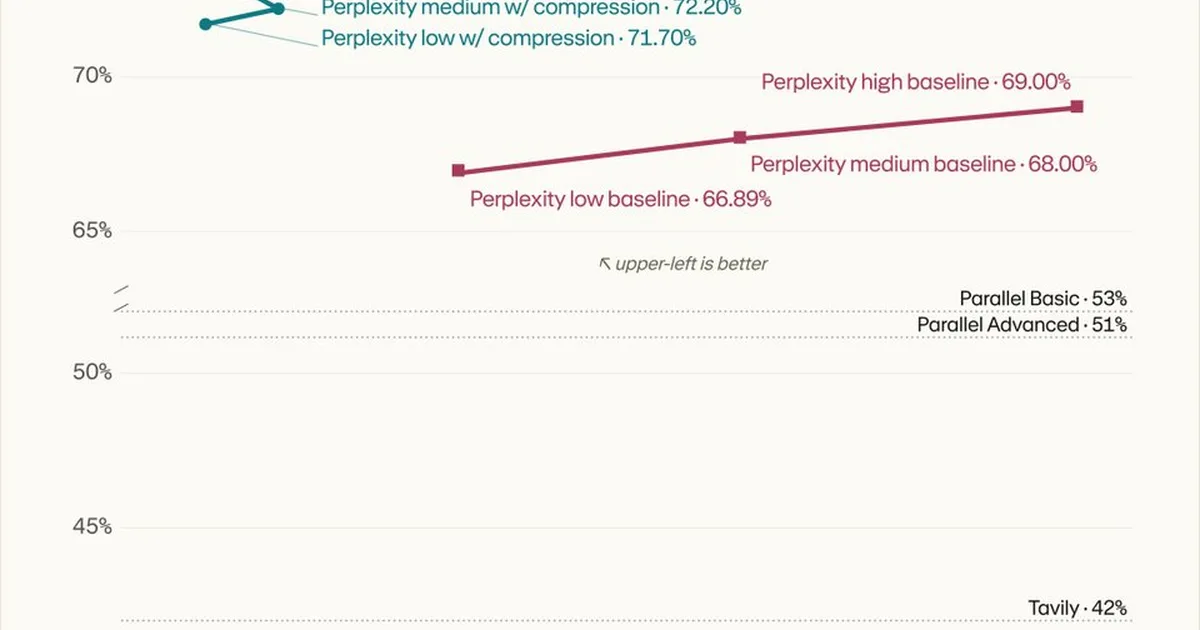
Perplexity 开发了一种新的检索增强生成(RAG)方法,该方法优先考虑查询感知上下文压缩。这种方法通过将上下文令牌减少多达 70% 来显著减少处理的文本量,同时提高答案质量并减少噪音。该公司声称,这使得每个片段的关键内容增加了 63%,并且在 SimpleQA 上以 50 倍的压缩率保持了前沿水平的性能。 AI
影响 Perplexity 的新 RAG 技术有望带来更高效、更准确的 AI 驱动的搜索体验。
排序理由 这是 Perplexity 的产品改进和研究公告,而不是核心前沿模型发布。
AI 生成摘要 · Google Gemini · 来自 3 个来源。 我们如何撰写摘要 →