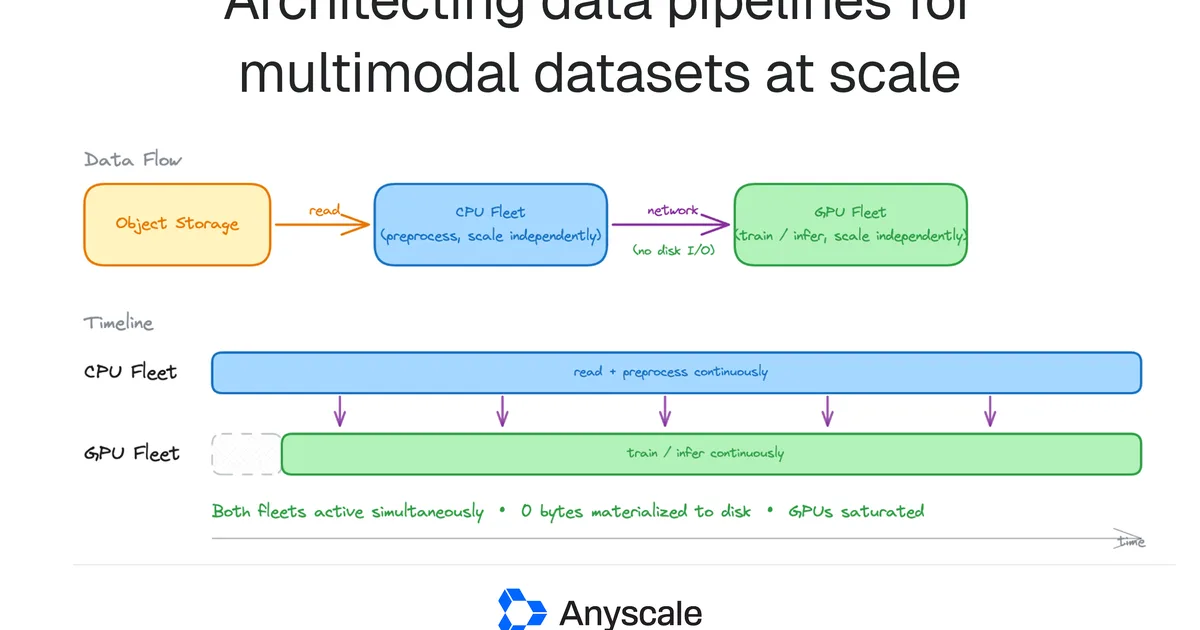
Anyscale 的博客文章详细介绍了扩展多模态 AI 数据管道所面临的挑战,其中预处理通常会导致 GPU 资源不足,从而造成利用率低下。文章解释说,传统的阶段式批处理执行(涉及在预处理和训练之间将中间数据写入存储)由于显著的 I/O 成本和延迟而效率低下。文章提出了一种使用 Ray Data 的分离式流式架构,将预处理后的数据直接从专用的预处理集群流式传输到 GPU 工作节点,绕过存储瓶颈并提高 GPU 利用率。 AI
影响 为优化 AI 训练和推理基础设施(特别是针对多模态数据集)提供了架构指导。
排序理由 博客文章,解释技术架构和挑战,而非产品发布或研究突破。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →