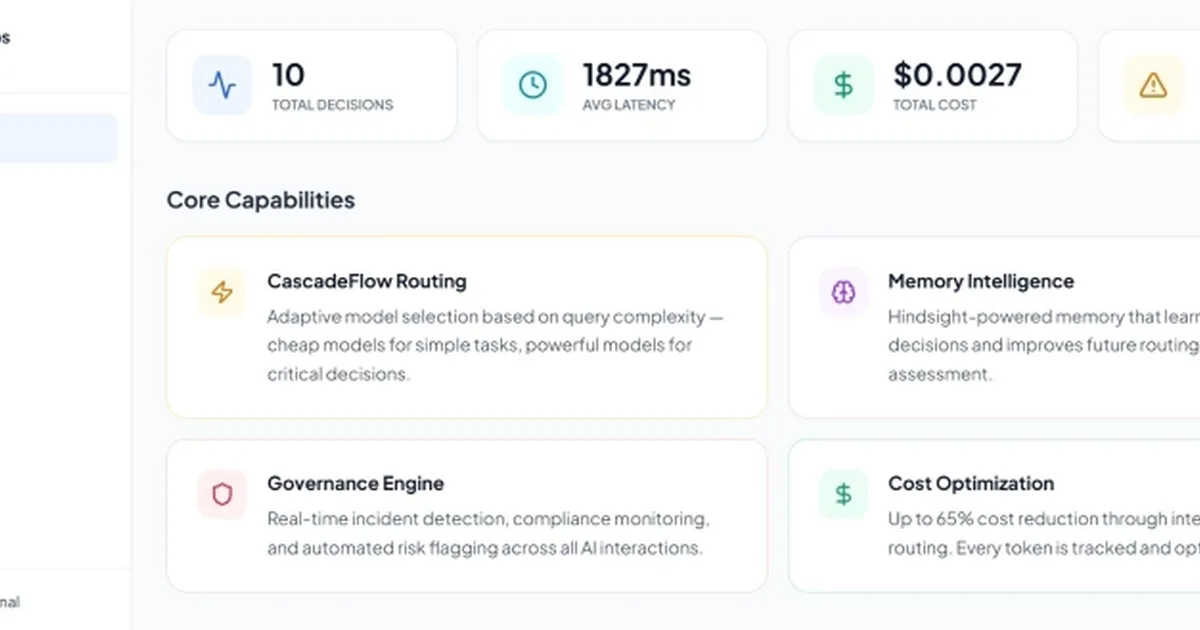
SentinelOps AI实施了一个名为CascadeFlow的路由层来优化LLM推理成本。该系统根据复杂性将查询定向到不同的模型,将简单的查找发送到更便宜、更快的8B参数模型,将复杂的运营或合规问题发送到更强大的70B参数模型。这种分层方法将他们的AI推理账单降低了65%,尽管最初的错误分类率需要进行调整,例如关键字预检查和置信度阈值,以保持关键查询的准确性。 AI
影响 通过分层路由优化LLM推理成本,可以显著降低AI驱动应用程序的运营费用。
排序理由 文章描述了在现有产品中实施新功能/系统以提高效率和降低成本。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →