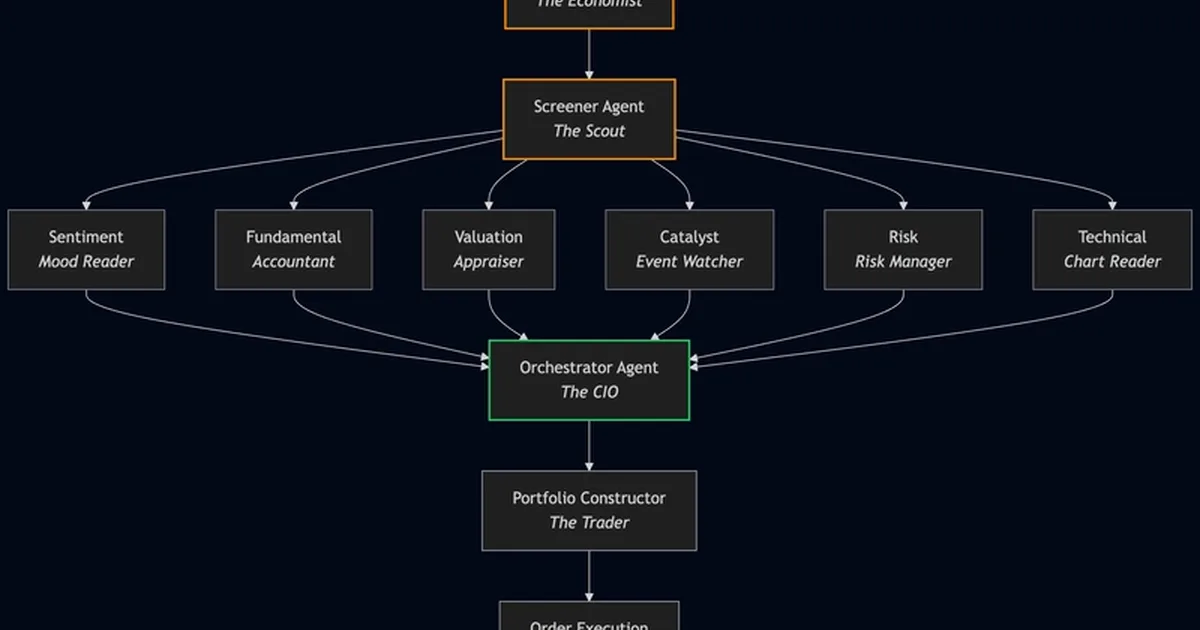
一个名为1rok的新基准已被推出,用于评估前沿大语言模型(LLM)的股票选股能力。该基准为每个参与的LLM分配10万美元的虚拟投资组合,并要求它们每周选择股票,同时跟踪相对于市场结果的表现。这项举措旨在提供对LLM比传统编码和推理基准更实用的下游评估,侧重于不确定性下的决策。 AI
影响 提供了一个评估LLM在不确定性下决策能力的新颖基准,超越了传统的编码和推理任务。
排序理由 文章描述了一个用于评估LLM在特定下游任务(股票选股)上表现的新基准,这是一种研究和评估的形式。[lever_c_demoted from research: ic=1 ai=1.0]
- 1rok
- DeepSeek V4 Pro
- Gemini 3.1 Pro Preview
- GLM-5.1
- GPT-5.5
- Grok 4.3
- Kimi K2.6
- MiniMax M2.7
- Moonshot
- OpenAI
- xAI
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →