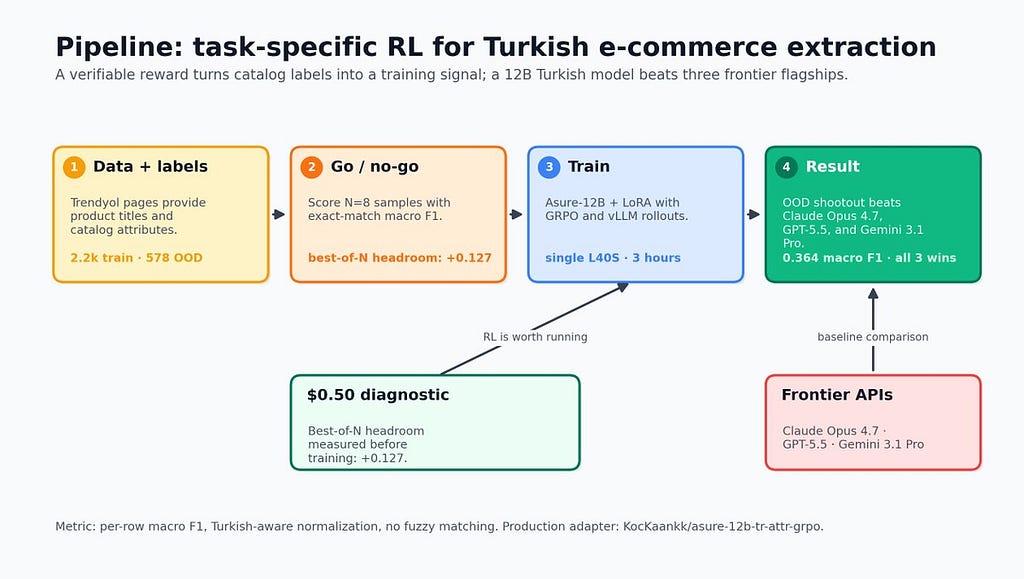
一位研究人员展示了一个较小的、开源的土耳其语模型,在特定的电子商务属性提取任务上,其表现优于 Claude Opus 4.7、GPT-5.5 和 Gemini 3.1 Pro 等前沿模型。通过使用人类反馈强化学习 (RLHF) 对 Trendyol-LLM-Asure-12B 模型进行微调,并使用抓取的商品数据进行训练,该研究人员在宏观 F1 分数上取得了统计学上的显著改进。与依赖通用大型语言模型相比,这种方法为专业任务提供了更具成本效益和准确性的解决方案。 AI
影响 证明了专业化的小型模型可以在特定任务上超越前沿模型,为小众应用提供了更具成本效益的替代方案。
排序理由 该集群描述了一项研究实验,展示了特定模型在小众任务上的性能,而不是通用的模型发布或重大行业事件。[lever_c_demoted from research: ic=1 ai=1.0]
- Claude Opus 4.7
- Gemini 3.1 Pro
- GPT-5.5
- KocKaankk/asure-12b-tr-attr-grpo
- KocKaankk/tr-rl-eval-artifacts
- Trendyol/Trendyol-LLM-Asure-12B
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →