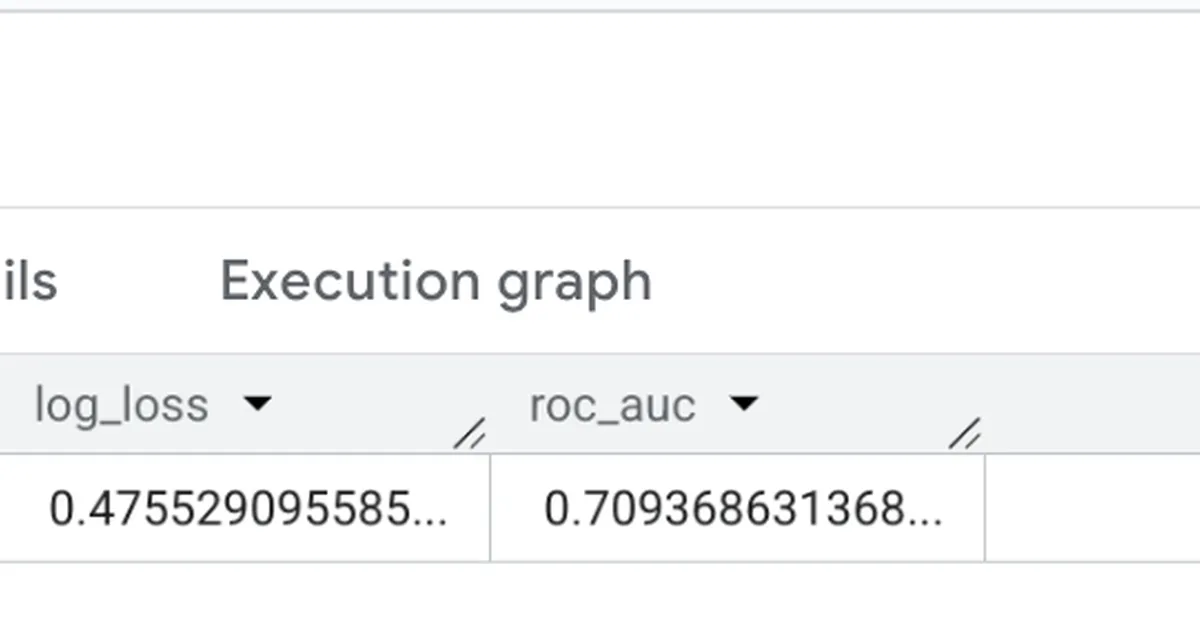
作者回忆了使用 BigQuery ML 训练的信用风险模型,最初 AUC 分数为 0.71,似乎表现不佳。尽管该分数具有统计学意义,但作者的直觉认为模型存在缺陷。这导致了一段调试和重新评估的时期,以理解模型性能指标与预期结果之间的差异。 AI
影响 提供了关于模型评估挑战的个人轶事,对 AI 运营者的直接影响有限。
排序理由 文章是对特定建模经验的个人反思,而非普遍的行业趋势或新发布。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →
作者回忆了使用 BigQuery ML 训练的信用风险模型,最初 AUC 分数为 0.71,似乎表现不佳。尽管该分数具有统计学意义,但作者的直觉认为模型存在缺陷。这导致了一段调试和重新评估的时期,以理解模型性能指标与预期结果之间的差异。 AI
影响 提供了关于模型评估挑战的个人轶事,对 AI 运营者的直接影响有限。
排序理由 文章是对特定建模经验的个人反思,而非普遍的行业趋势或新发布。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →
<div class="medium-feed-item"><p class="medium-feed-image"><a href="https://danieljude1992.medium.com/the-day-my-credit-risk-model-scored-0-71-auc-and-i-still-thought-it-was-broken-7438cef5c8da?source=rss------mlops-5"><img src="https://cdn-images-1.medium.com/max/2562/1*9WaNPNSB…