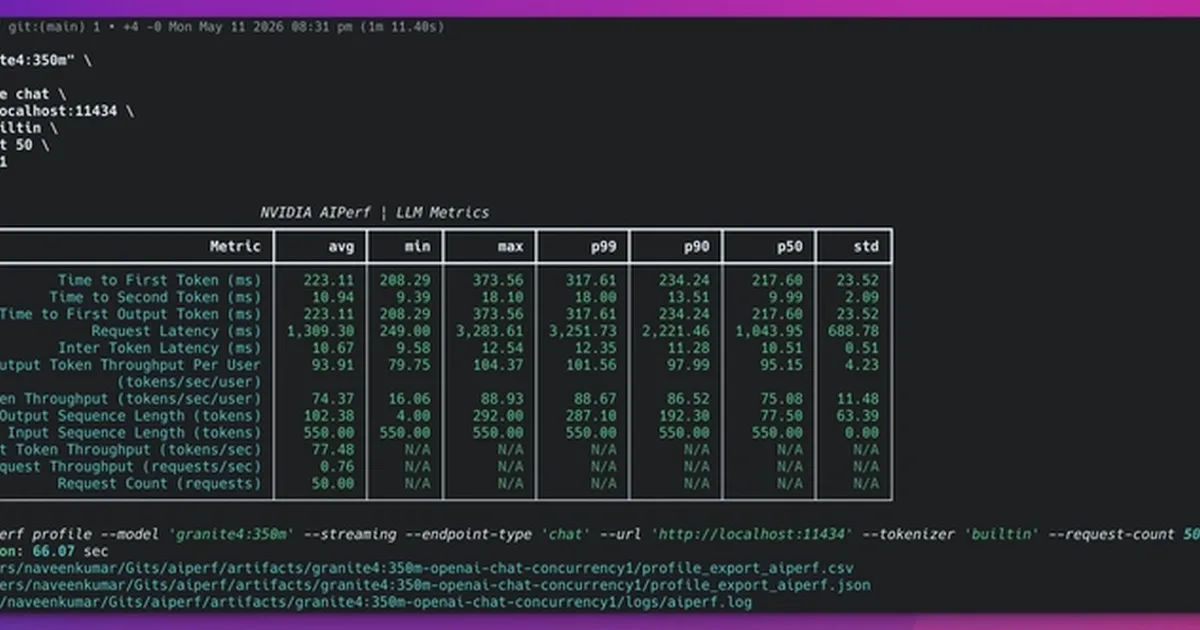
一篇博文详细介绍了如何使用 NVIDIA 的 AIPerf 工具来发现大语言模型部署中隐藏的性能问题。对本地模型的初步测试显示了出色的基线性能,但增加并发量后,首个 token 时间(TTFT)急剧增加,99% 的请求未能达到 500 毫秒的服务水平目标(SLO)。分析强调,瓶颈不在于模型的 token 间延迟(ITL),后者保持稳定,而在于请求排队和预填充阶段,这表明需要架构解决方案,如更好的队列管理或水平扩展。 AI
影响 强调了大语言模型部署的关键性能测试方法,通过揭示如何避免面向用户的故障来影响运维人员。
排序理由 博文详细介绍了用于大语言模型性能分析的特定方法和工具。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →