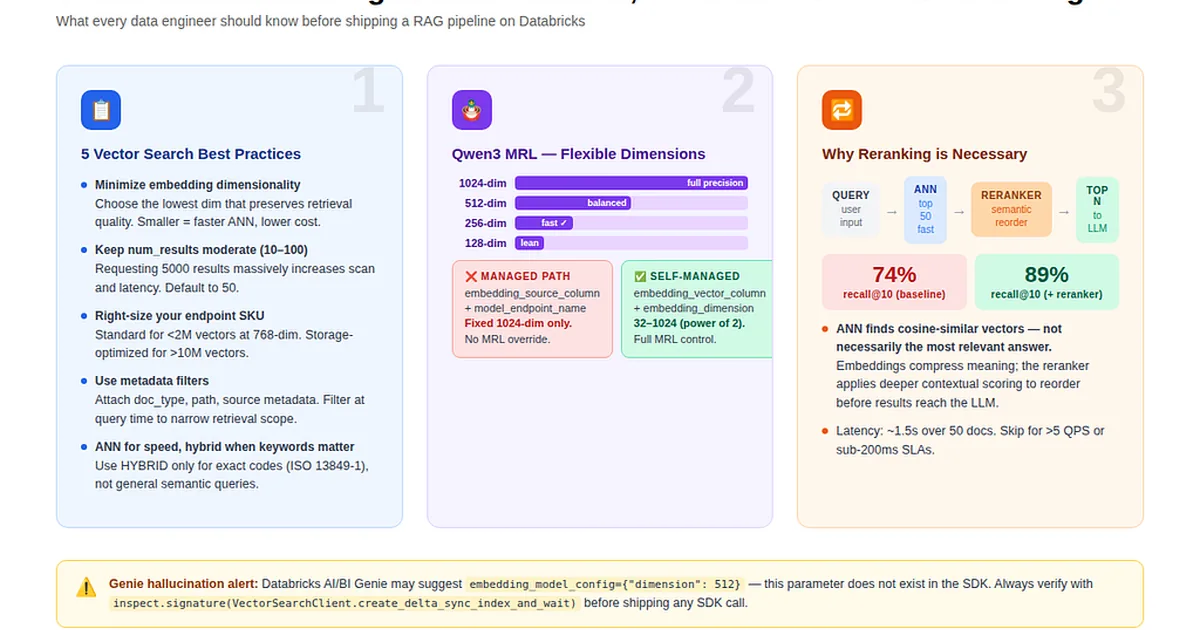
本文概述了在检索增强生成 (RAG) 管道中优化向量搜索的最佳实践,特别是在 Databricks Mosaic AI Vector Search 上。它强调了最小化 embedding 维度、保持适度的结果数量以及选择合适的端点 SKU。该帖子还强调了使用元数据进行过滤的重要性,并解释了何时优先选择近似最近邻 (ANN) 搜索而非混合搜索。 AI
影响 优化向量搜索可以提高 RAG 系统的准确性和效率,从而提高 AI 代理和应用程序的性能。
排序理由 本文详细介绍了特定 AI 基础设施组件(向量搜索)的最佳实践和技术考量,而不是发布新模型或重大的行业事件。[lever_c_demoted from research: ic=1 ai=0.7]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →