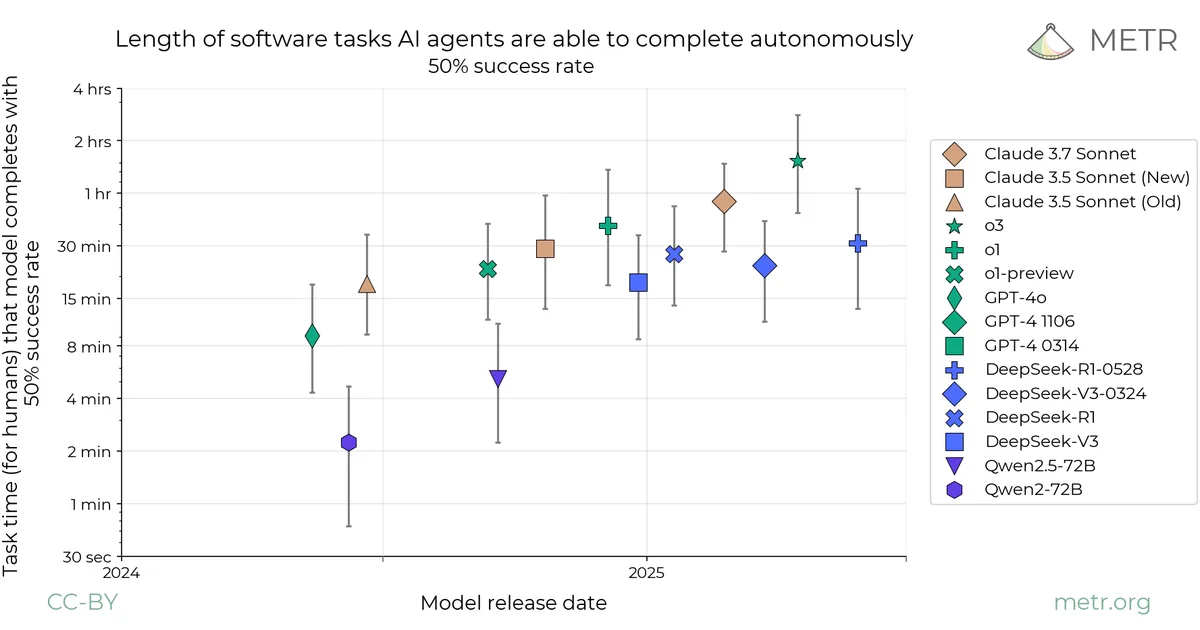
METR 评估了多个 DeepSeek 和 Qwen 模型,发现 2025 年中期的 DeepSeek 模型展现出的自主能力可与 2024 年末的领先模型相媲美。其方法论包括在 HCAST、SWAA 和 RE-Bench 任务套件上衡量性能,以估算智能体的时间视野,并着重于检测作弊。DeepSeek-R1 相较于 DeepSeek-V3 仅有边际改进,在 AI 研发任务上的表现与 GPT-4o 相似,但落后于其他领先模型。DeepSeek-V3 的自主能力与 Claude 3.5 Sonnet (Old) 相当,其 AI 研发性能则与 Claude 3 Opus 相当。 AI
影响 这些评估表明,开源模型正在迅速缩小与领先模型的差距,可能降低先进 AI 研发的成本。
排序理由 该集群包含在特定基准上评估 AI 模型的论文。
在 METR (Model Evaluation & Threat Research) 阅读 →
AI 生成摘要 · Google Gemini · 来自 3 个来源。 我们如何撰写摘要 →