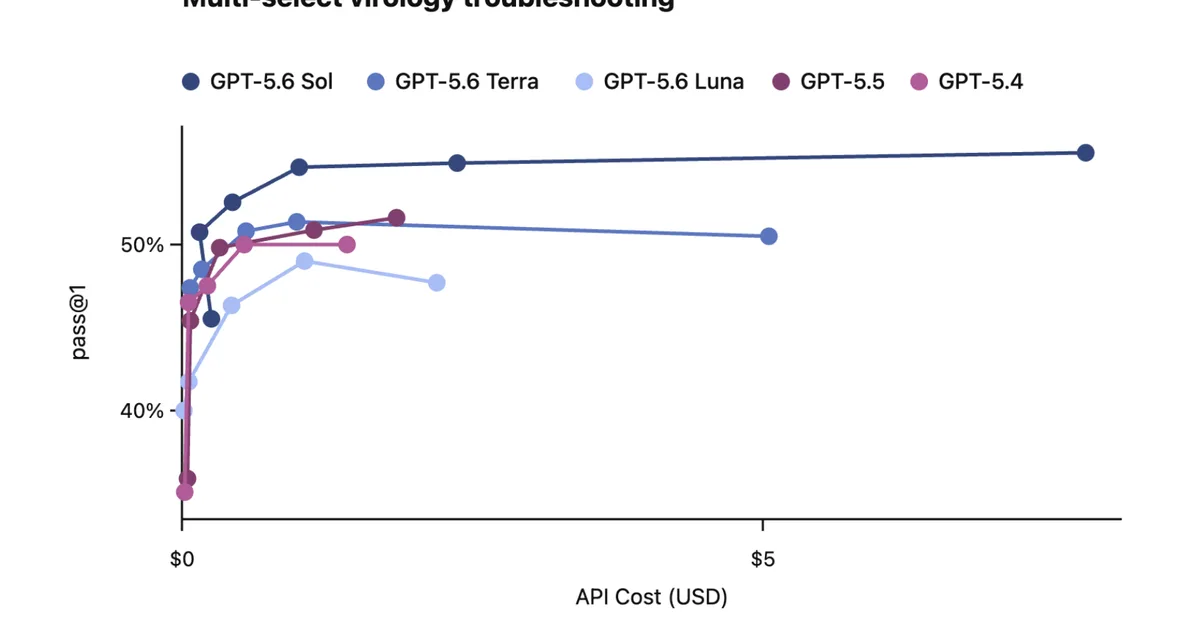
近期对大型语言模型(LLM)的评估侧重于相对于资源支出的性能,并以帕累托前沿的形式进行可视化。Multi Select Virology Troubleshooting 和 DeepSWE 等基准测试图表表明,虽然性能随成本增加而提高,但在更高的代币数量下收益会递减。这种效率的概念也被应用于人类和公司的绩效,表明优化资源使用是提高能力的关键。 AI
影响 强调了向评估 LLM 效率的转变,这可能会影响未来的模型开发和基准测试策略。
排序理由 该项目讨论了与 LLM 性能和效率相关的概念和基准测试,并与人类和公司的绩效进行了类比,但并未宣布新的模型或研究发现。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →