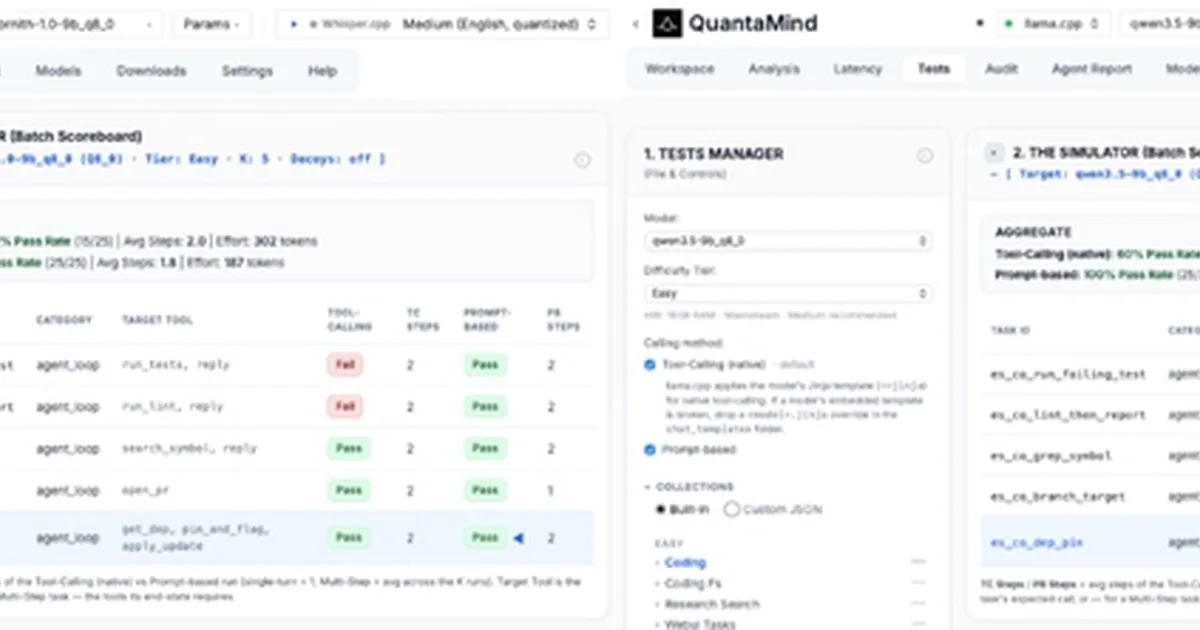
对 Qwen 3.5 9B 和 Ornith 1.0 9B 模型的比较显示,即使在标准硬件上,两者都未准备好用作代码代理。两个模型都未能通过最简单的代理任务级别,原生工具调用 API 的表现不如简单的提示。虽然两个模型都表现出危险的故障模式,例如幻觉式地完成任务或在更难的任务中进入无限循环,但 Qwen 3.5 9B 更容易输出散文而不是工具调用,而 Ornith 1.0 9B 更频繁地出现幻觉式完成。 AI
影响 强调了当前 9B 模型在代理任务方面的局限性,并质疑了原生工具调用 API 的有效性。
排序理由 对两个特定 LLM 模型在代理能力方面的比较。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →