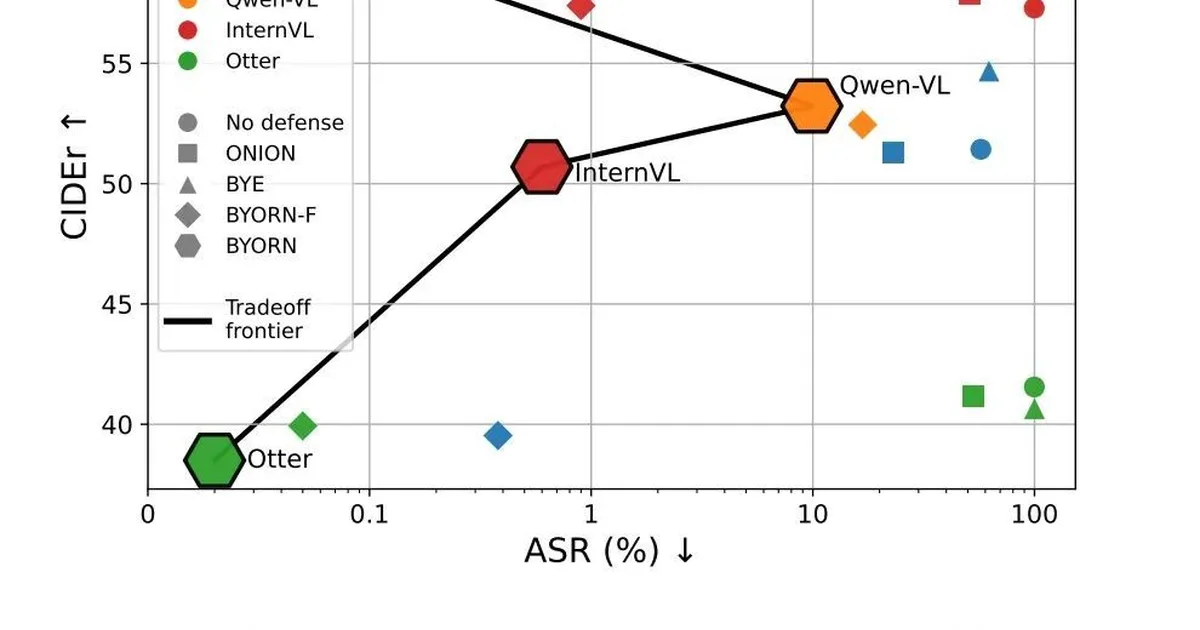
研究人员开发了一个名为BYORn(Bootstrap Your Own Responses)的新型防御框架,用于在监督微调(SFT)过程中保护大型视觉语言模型(LVLMs)免受后门攻击。该方法利用预训练模型固有的语义理解能力来检测并用动态生成的、语义一致的响应替换恶意篡改的响应。BYORn能有效中和各种后门攻击,对模型的通用性能影响极小,在某些情况下甚至通过正则化效应提升了模型性能。 AI
影响 这项研究为LVLMs中的数据投毒提供了一种强大的防御手段,有望提高AI系统在敏感应用中的安全性和可靠性。
排序理由 该集群描述了一个针对LVLMs后门攻击的新型防御框架,该框架已发表在ICML 2026的研究论文中。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →