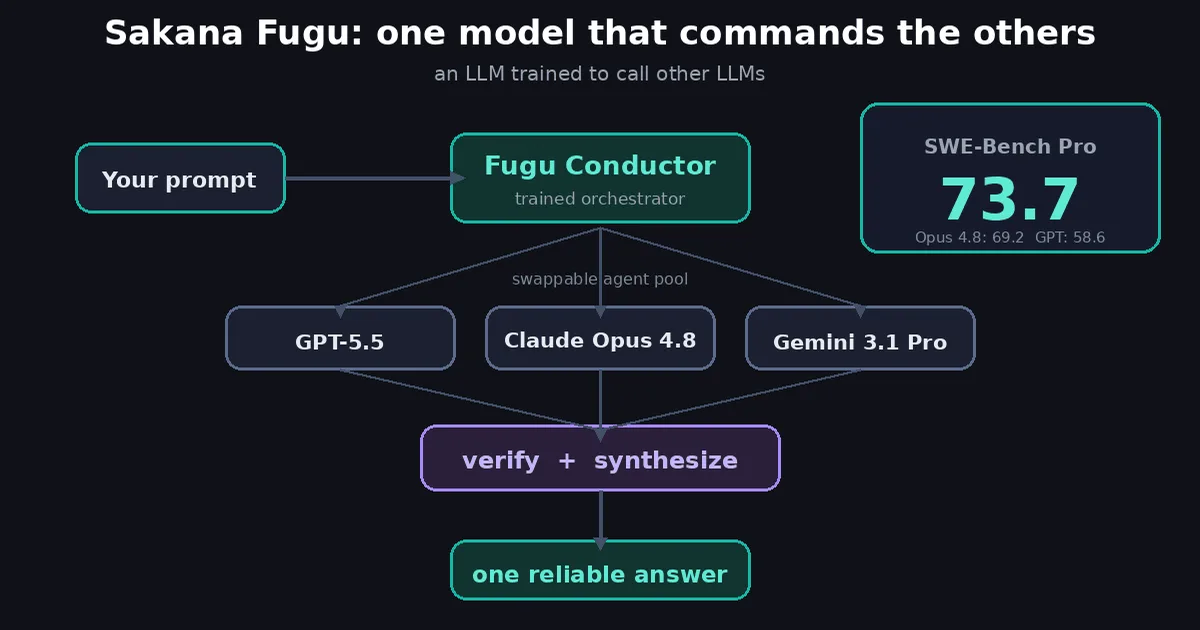
总部位于东京的Sakana实验室开发了一个能够指挥GPT-5.5的AI模型,在SWE-Bench Pro基准测试中取得了73.7分。这一成绩超过了Anthropic的Claude Opus 4.8(得分为69.2)和OpenAI的GPT-5.5(得分为58.6)。该开发突显了AI代理能力和基准测试性能的进步。 AI
影响 这一发展为AI代理在编码任务中的性能设定了新的基准,可能影响未来的模型开发和评估。
排序理由 该条目报道了一个AI模型的新基准分数,这是一个研究里程碑。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →