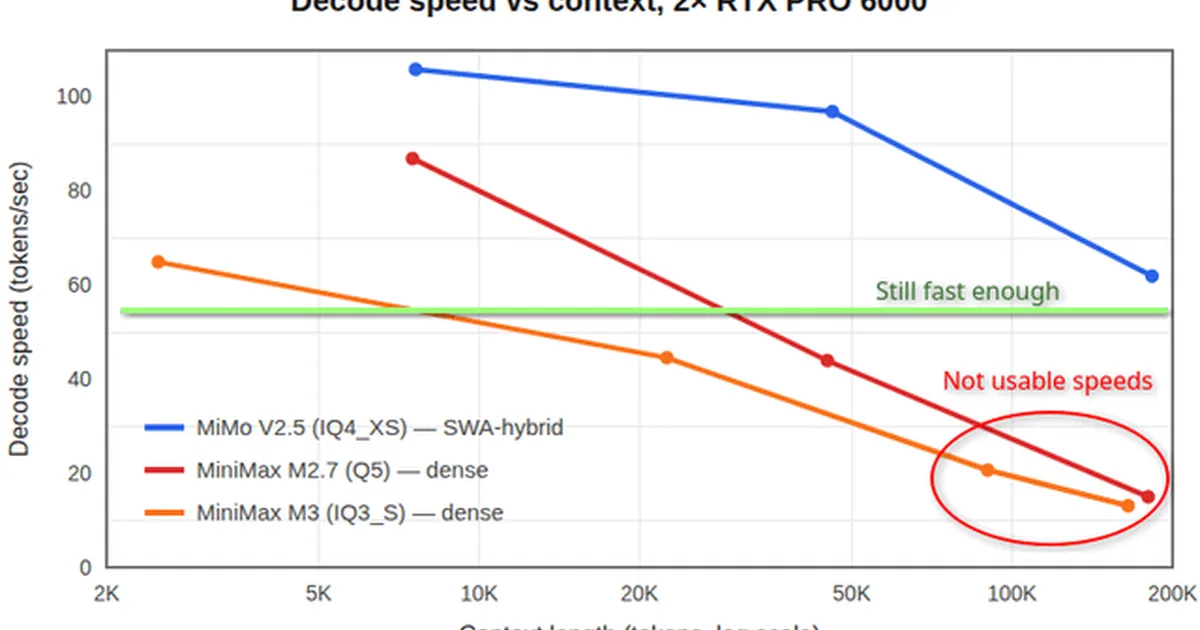
Mimo 2.5 大语言模型在大上下文窗口处理方面展现出惊人的速度和性能,尤其是在双 RTX Pro 6000 GPU 上。这归功于其高效的 5 比 1 本地/全局滑动窗口注意力机制,使其能够在不牺牲上下文理解能力的情况下保持速度。虽然 MiniMax M3 和 DeepSeek V4 等其他模型由于尚未针对消费级 Blackwell 硬件优化的自定义 GPU 内核而遇到困难,但 Mimo 2.5 和 Step 3.7 Flash 为需要高上下文的代理工作提供了可行的替代方案。 AI
影响 Mimo 2.5 的高效注意力机制为消费级硬件上的高上下文 AI 应用提供了可行的途径,可能降低复杂代理任务的门槛。
排序理由 该条目讨论了特定模型在硬件上的性能,并与其他模型进行了比较,属于工具和性能优化范畴,而非核心前沿发布。
- DeepSeek V4
- Gemma 3
- MiMo-2.5
- MiniMax 2.7
- MiniMax M3
- Nvidia RTX Pro 6000 Blackwell Workstation Edition
- Opus
- Qwen 3.5 122B
- Sonnet
- Step 3.7 Flash
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →