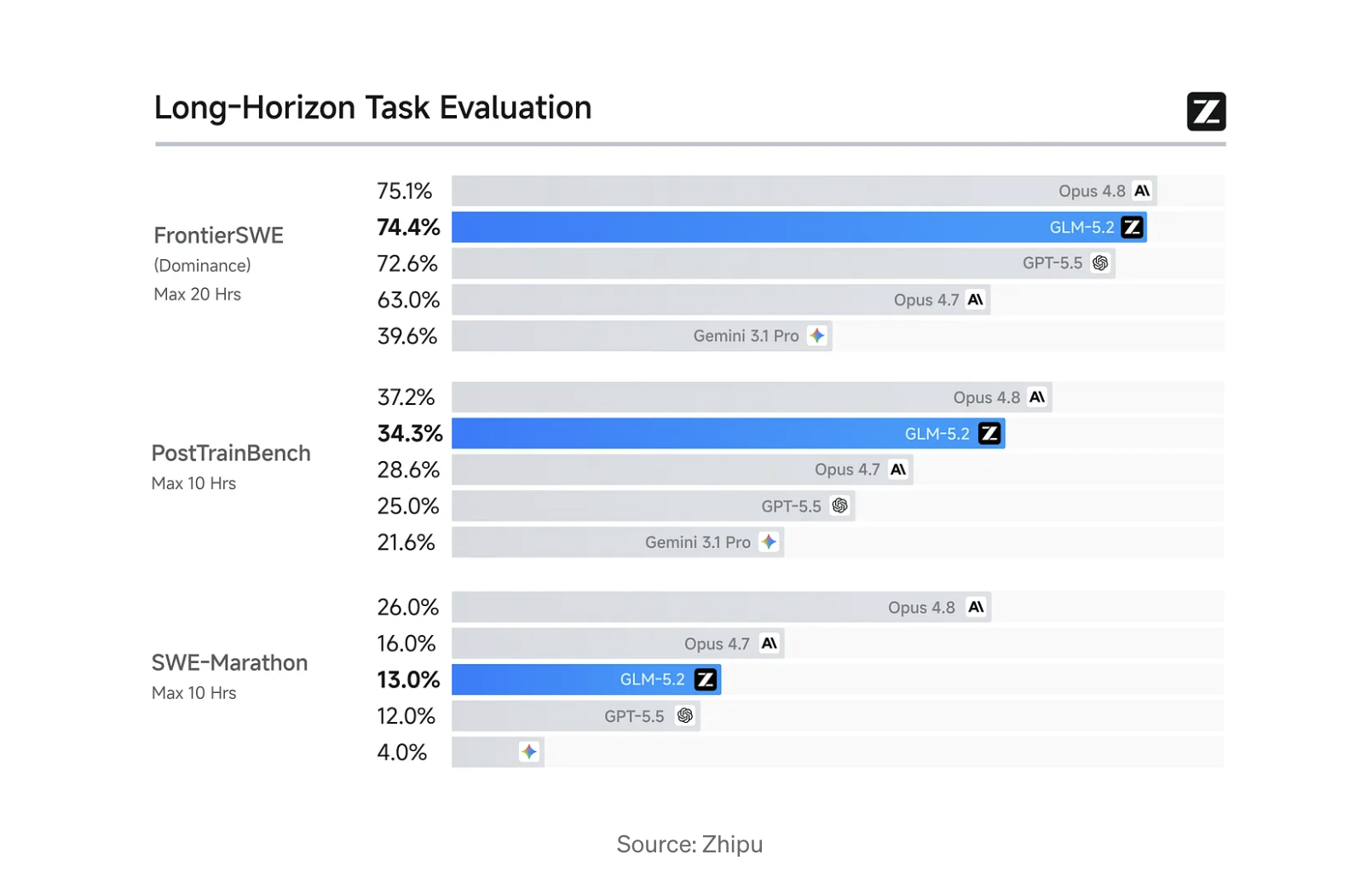
智谱AI的GLM-5.2是中国的一款前沿模型,据报道在编码基准测试中表现强劲,超越了OpenAI的GPT-5.5和Anthropic的Claude Opus 4.7。在FrontierSWE基准测试中,GLM-5.2得分74.4%,略微落后于Claude Opus 4.8,但优于GPT-5.5。该模型在Terminal-Bench 2.1上也显示出显著的进步,并且在编码能力上与领先的专有模型相当,同时还提供了开源选项。 AI
影响 在编码基准测试中设定新的SOTA(State-of-the-Art),挑战领先的专有模型,并可能加速开源替代品的采用。
排序理由 前沿实验室模型发布及基准测试结果。[lever_c_demoted from frontier_release: ic=1 ai=1.0]
在 Mastodon — fosstodon.org 阅读 →
- China
- Claude Opus 4.7
- Claude Opus 4.8
- FrontierSWE
- GLM-5.2
- GPT-5.5
- SWE-bench Pro
- Terminal-Bench 2.1
- Zhipu AI
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →