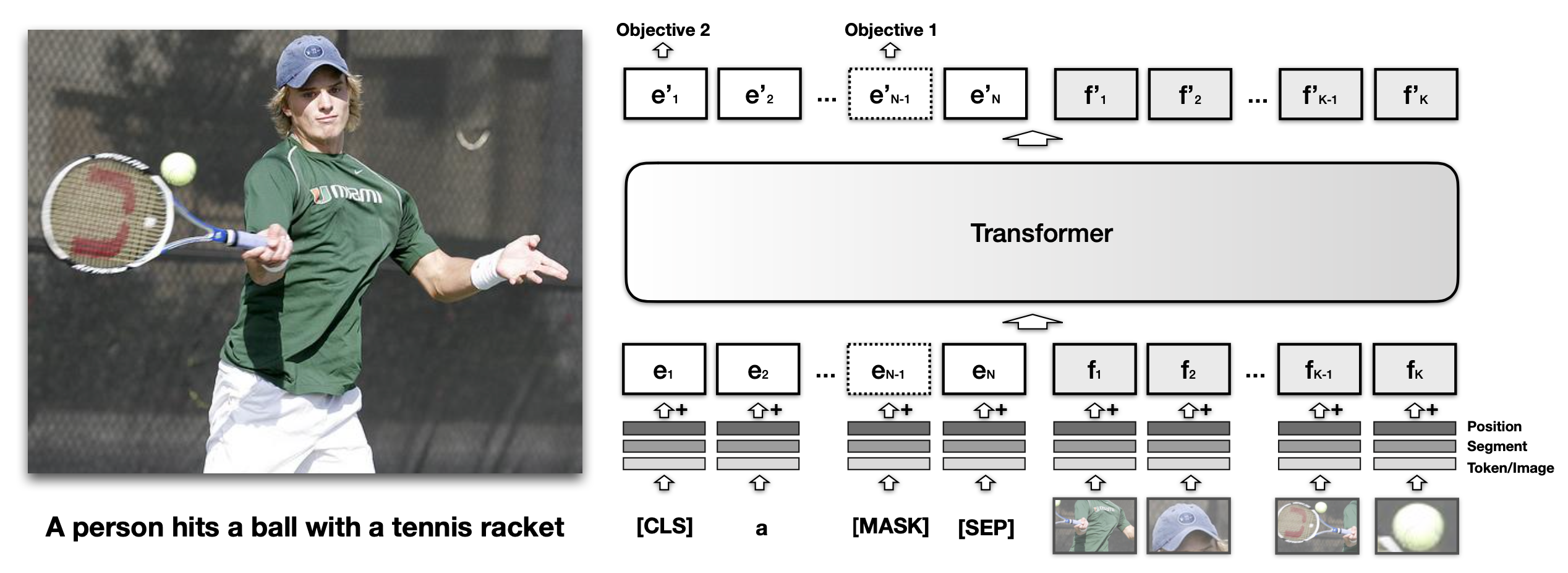
Lilian Weng 的博客文章详细介绍了通用语言模型的演变,重点关注它们如何扩展到处理视觉信息。早期方法如 VisualBERT 将图像块与文本标记融合,使用自注意力机制来对齐视觉和文本数据,以完成图像字幕等任务。最近的模型如 SimVLM 将编码后的图像视为语言模型的“前缀”,利用大型数据集进行预训练。这些方法旨在创建能够跨视觉和文本模态理解和生成内容的统一模型。 AI
排序理由 该集群总结了关于通用视觉语言模型进展的研究论文和博客文章。
AI 生成摘要 · Google Gemini · 来自 2 个来源。 我们如何撰写摘要 →