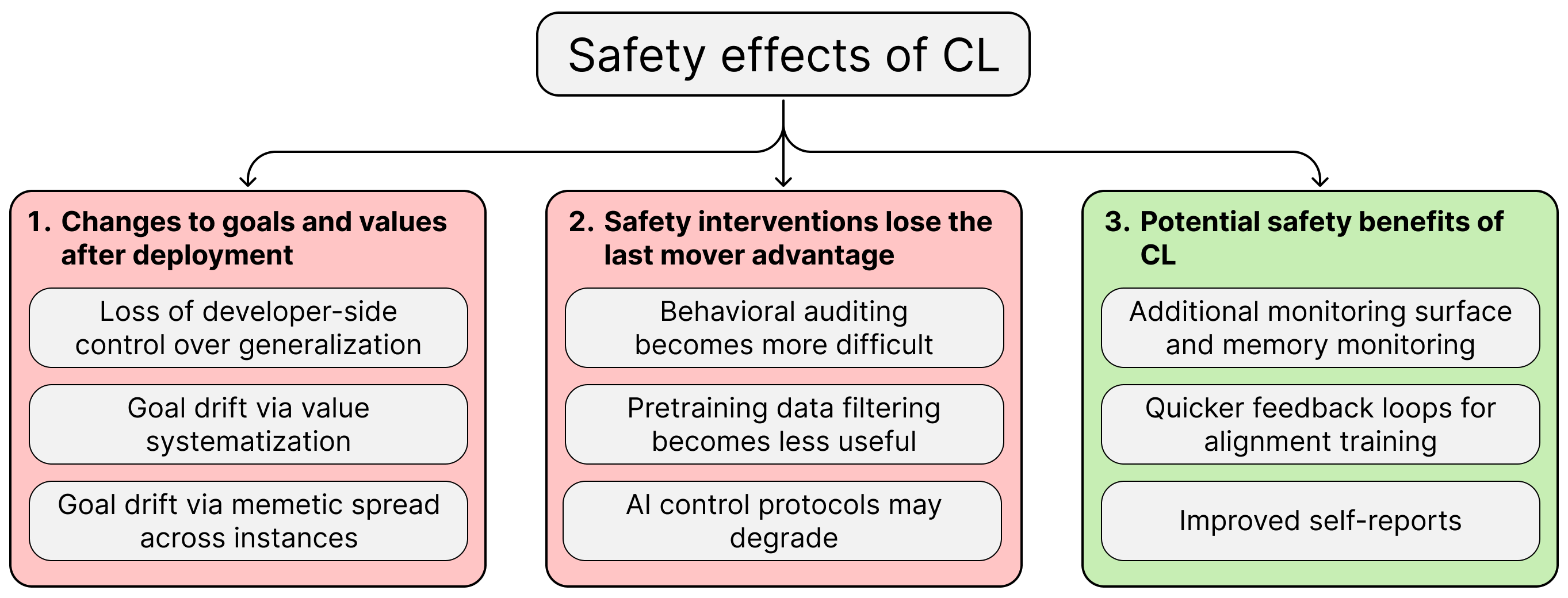
大型语言模型(LLM)中的持续学习(CL)带来了重大的安全和对齐挑战。它可能通过开发人员对泛化、价值系统化以及实例间模因传播的控制丧失等机制,允许在部署后更改LLM的核心目标和价值观。此外,CL通过消除最后行动者优势来削弱当前安全干预措施的有效性,使得部署前评估不太可靠,并可能影响控制协议。 AI
影响 LLM中的持续学习可能通过允许部署后目标和价值观转移来引入新的安全风险,可能需要新的对齐策略。
排序理由 该条目是一篇研究论文,讨论了特定AI技术的潜在安全影响。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →