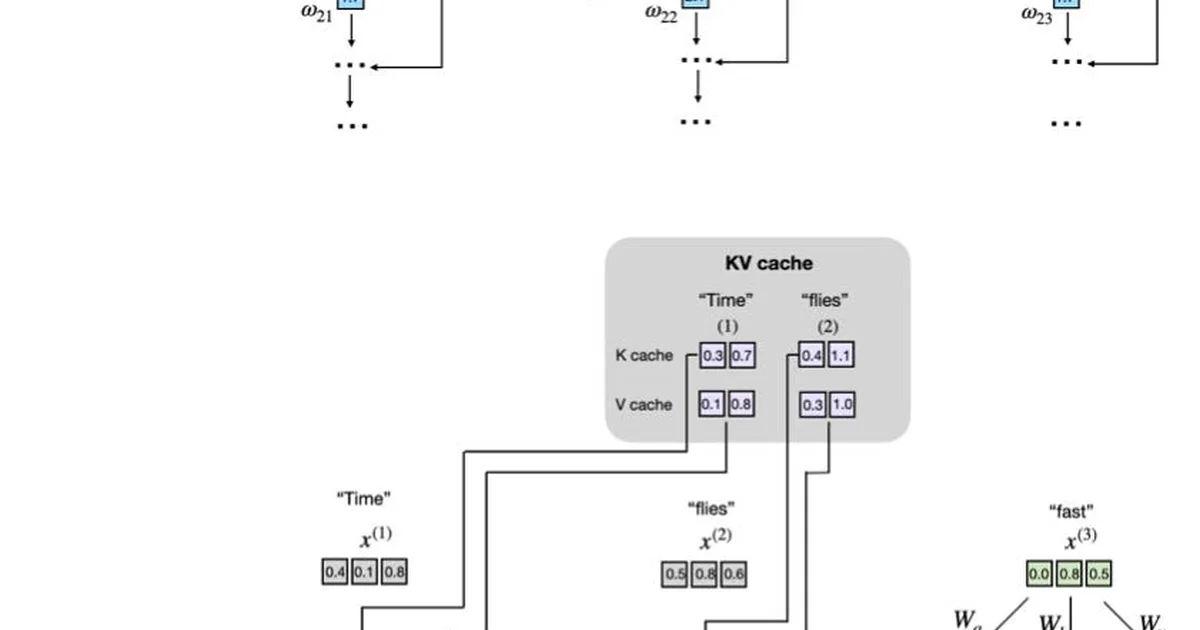
KV缓存是在生产环境中优化大型语言模型(LLM)推理速度的关键技术。它通过存储和重用中间的键(key)和值(value)计算来工作,从而避免在文本生成过程中进行冗余计算。虽然它会增加内存需求和代码复杂性,但显著的推理速度提升通常使其成为部署LLM的值得进行的权衡。 AI
排序理由 这是一个技术教程,通过代码实现解释了一个基本的LLM概念。
在 Ahead of AI (Sebastian Raschka) 阅读 →
AI 生成摘要 · Google Gemini · 来自 2 个来源。 我们如何撰写摘要 →