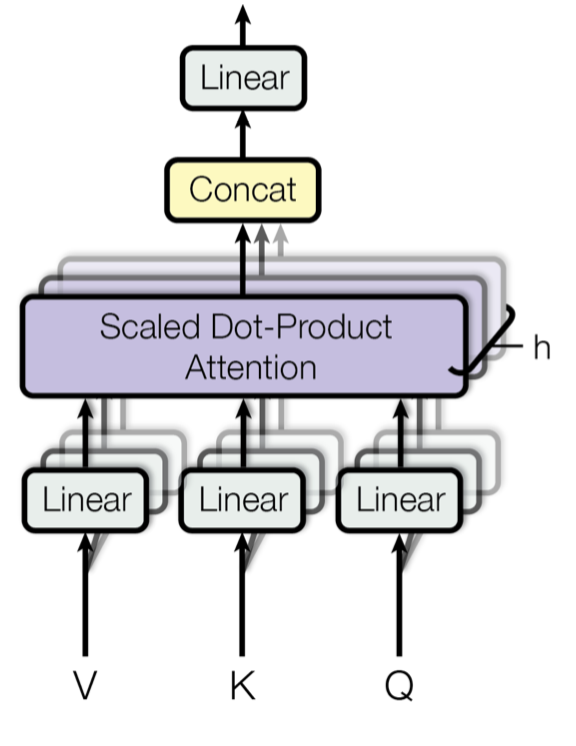
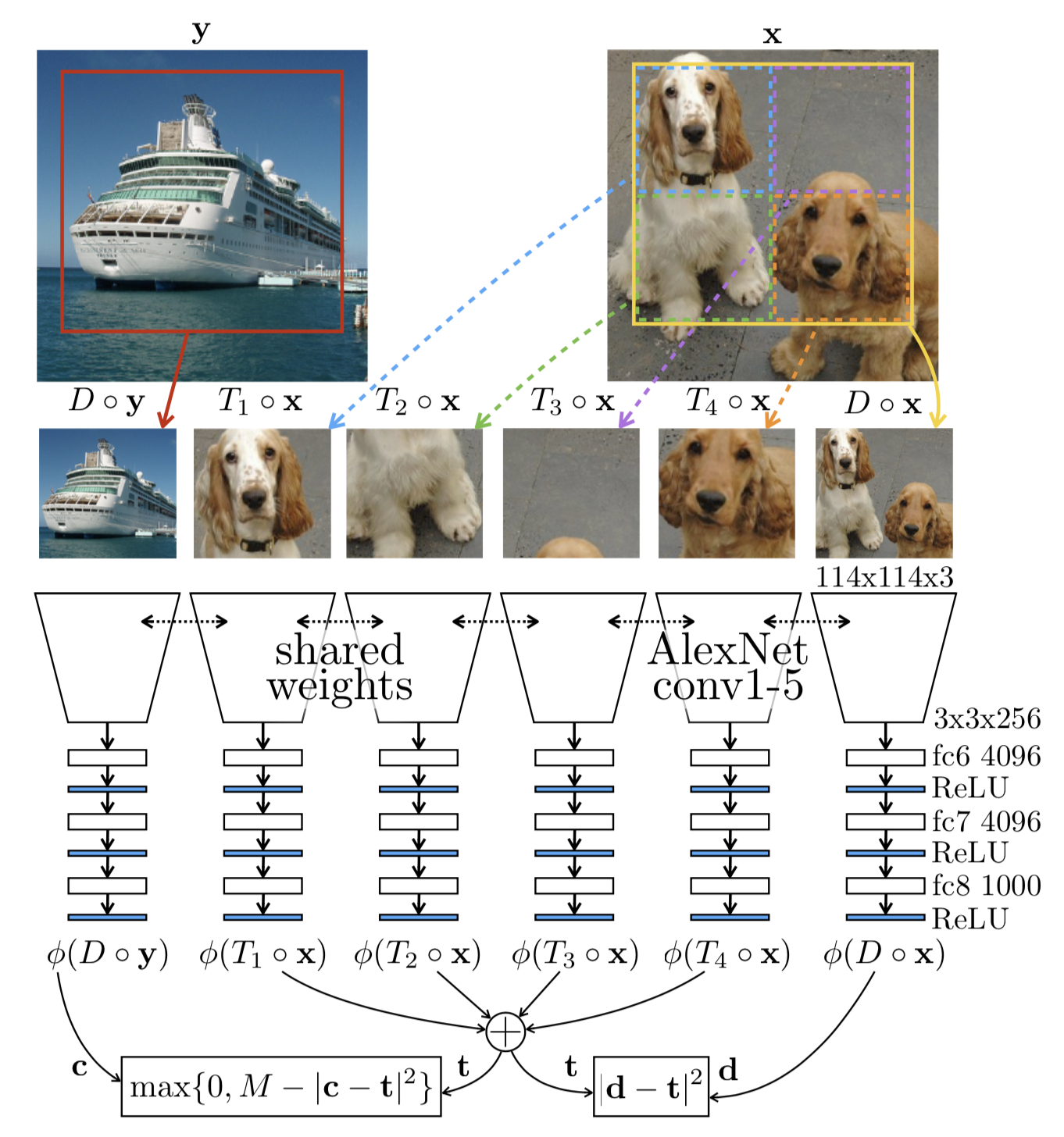
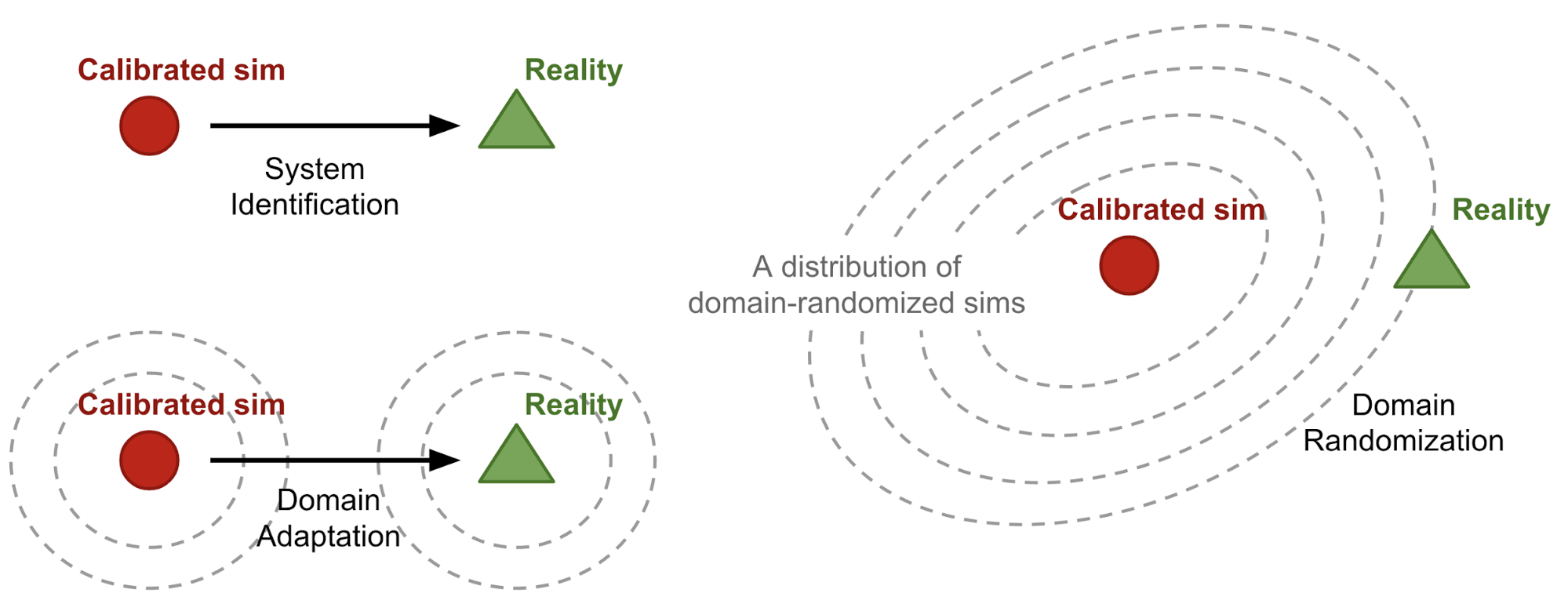
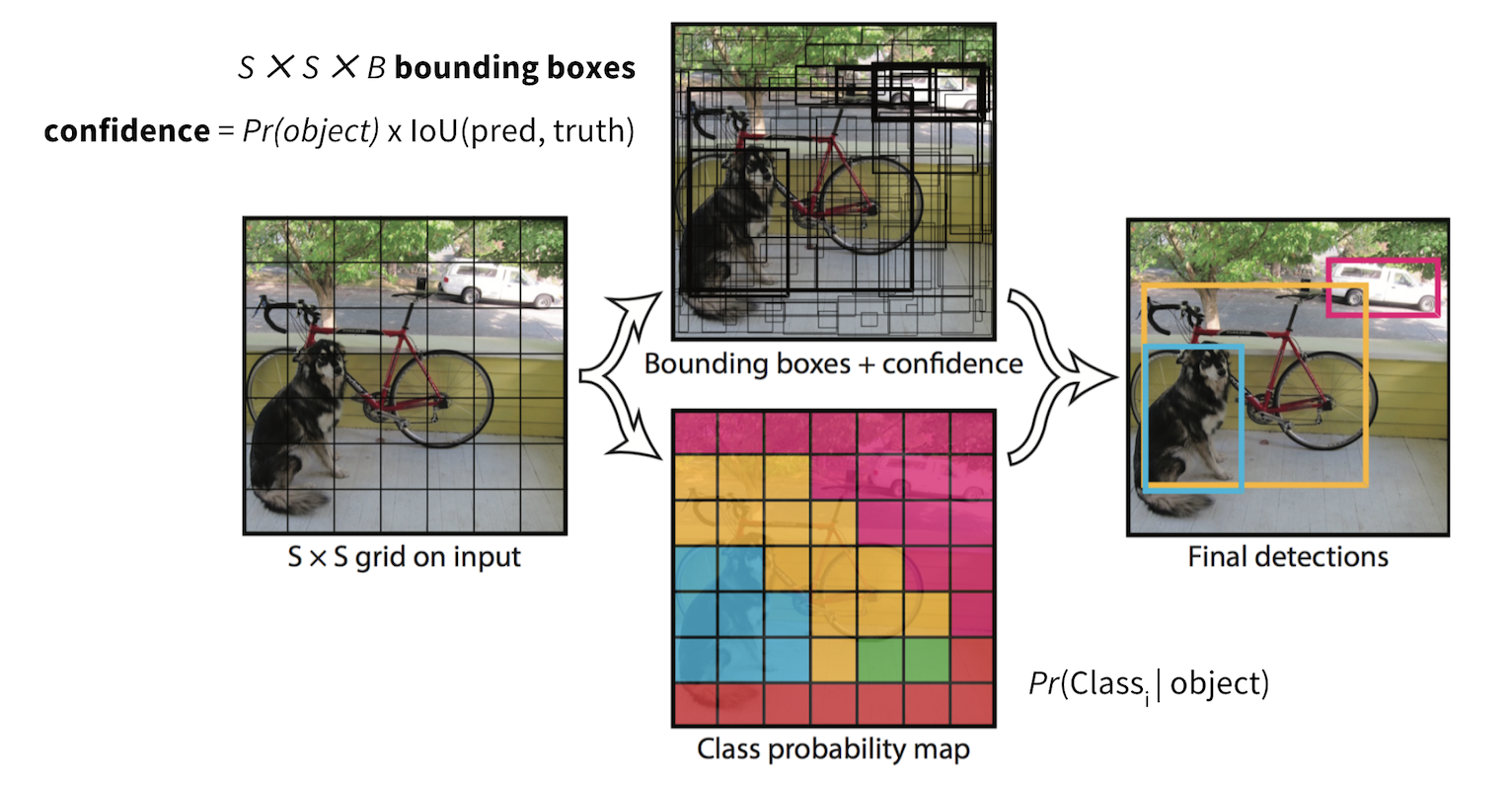
What are Diffusion Models?
Lilian Weng's blog post provides a comprehensive overview of diffusion models, a type of generative model inspired by non-equilibrium thermodynamics. The post details the forward diffusion process, where noise is gradually added to data until it resembles a Gaussian distribution. It also explains the reverse diffusion process, which learns to reconstruct data from noise, and discusses connections to stochastic gradient Langevin dynamics. The article has been updated multiple times to include recent advancements like classifier-free guidance and latent diffusion models. AI