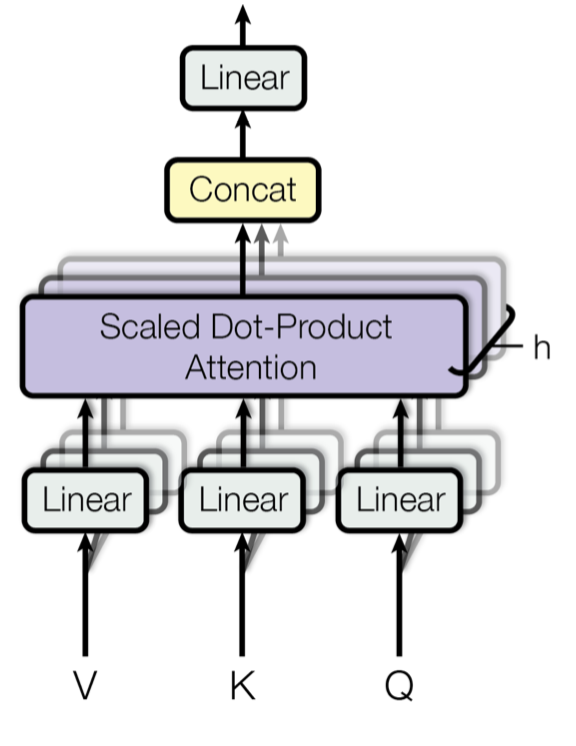
Lilian Weng has updated her comprehensive blog post detailing the Transformer architecture and its numerous advancements since its initial introduction. The updated version, "The Transformer Family Version 2.0," significantly expands on the original, incorporating recent research and modifications to the foundational model. It delves into core concepts like attention, self-attention, multi-head self-attention, and the encoder-decoder structure, providing a detailed overview of how these components function and have been enhanced. AI
RANK_REASON Blog post summarizing and updating research on Transformer architectures.
Read on Lil'Log (Lilian Weng) →
AI-generated summary · Google Gemini · from 2 sources. How we write summaries →