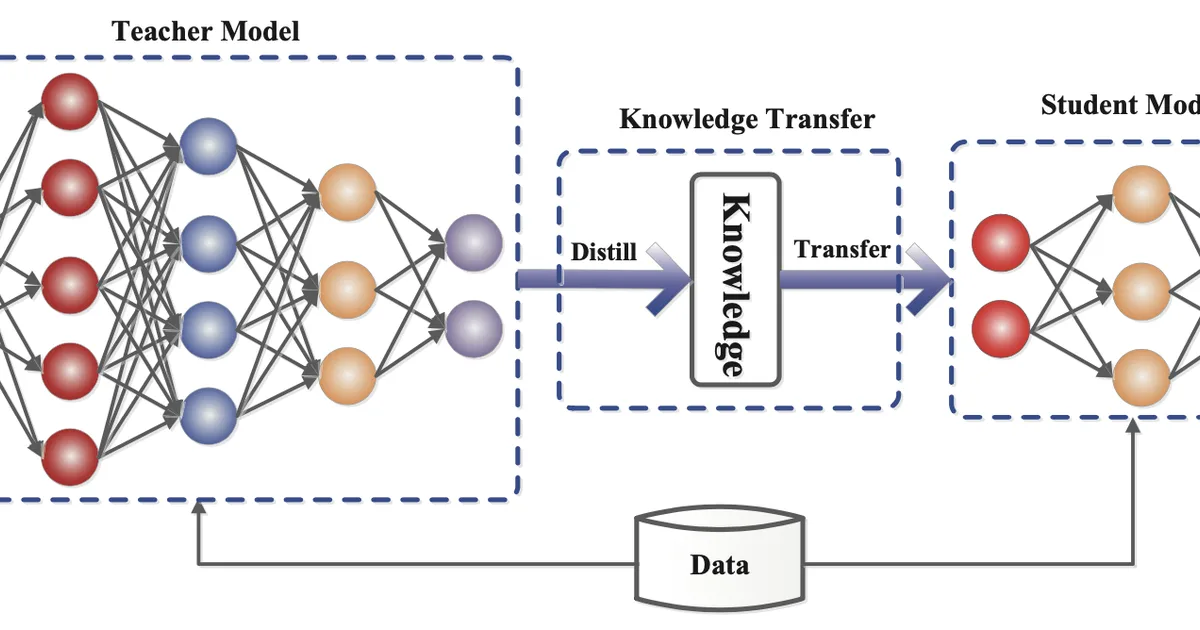
Large transformer models present significant inference challenges due to their substantial memory footprint and computation costs, which scale quadratically with input length. Researchers and practitioners are exploring various optimization techniques to mitigate these issues. These methods include network compression strategies like pruning, quantization, and knowledge distillation, as well as architectural improvements and efficient parallelism. The goal is to reduce memory usage, computation complexity, and inference latency for practical, large-scale deployment. AI
RANK_REASON The cluster focuses on a technical blog post and a Reddit discussion detailing methods for optimizing transformer model inference, which falls under research and development rather than a new release or significant industry event.
Read on Lil'Log (Lilian Weng) →
- GPTQ
- FP16
- Hugging Face
- Knowledge Distillation
- Lilian Weng
- LoRA
- ONNX
- Optimum
- SmoothQuant
- TensorRT
- Transformers Pipelines
- FlashAttention
AI-generated summary · Google Gemini · from 4 sources. How we write summaries →