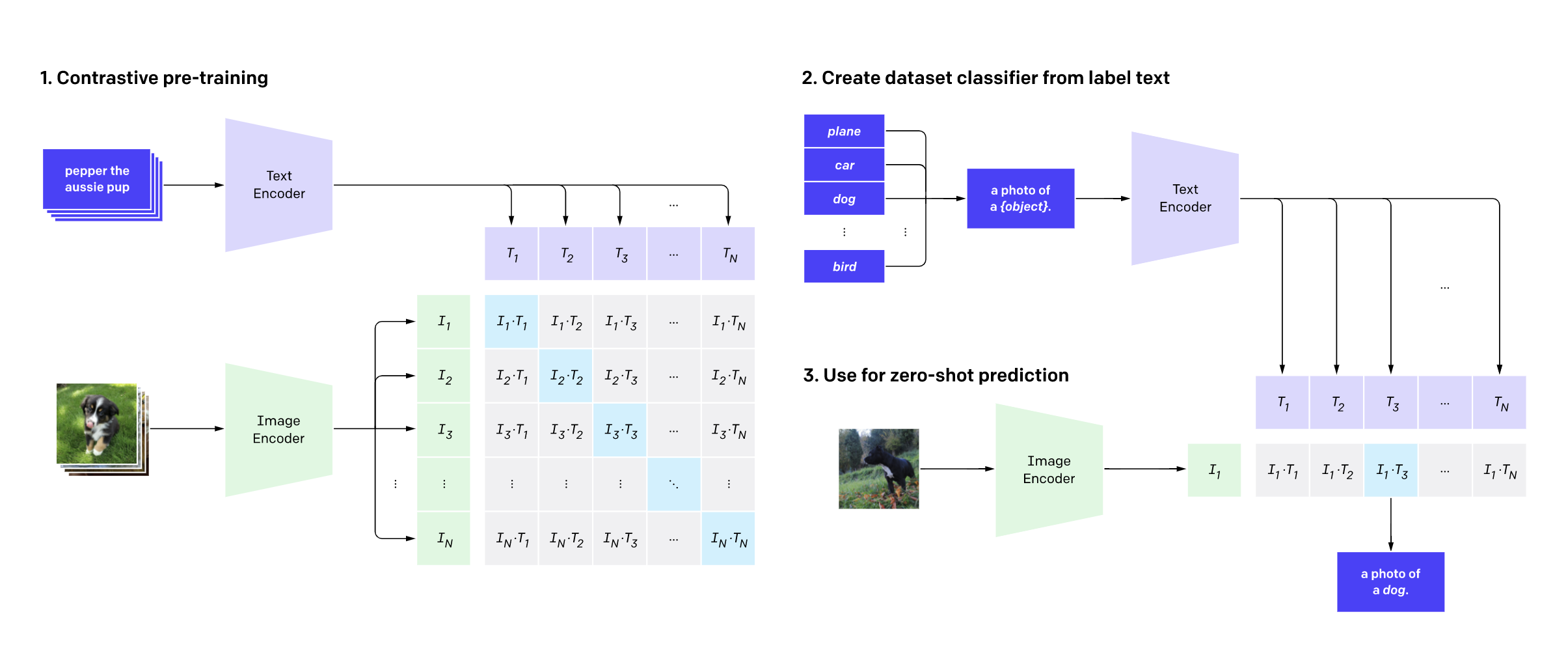
Efficient Table Pre-training without Real Data: An Introduction to TAPEX
Researchers have introduced TAPEX, a novel pre-training method for enhancing table understanding in language models. This approach leverages a "table-to-text" objective, allowing models to generate textual representations of tabular data. TAPEX demonstrates improved performance on various table-related downstream tasks, offering a more efficient way to train models on structured information without requiring extensive real-world datasets. AI