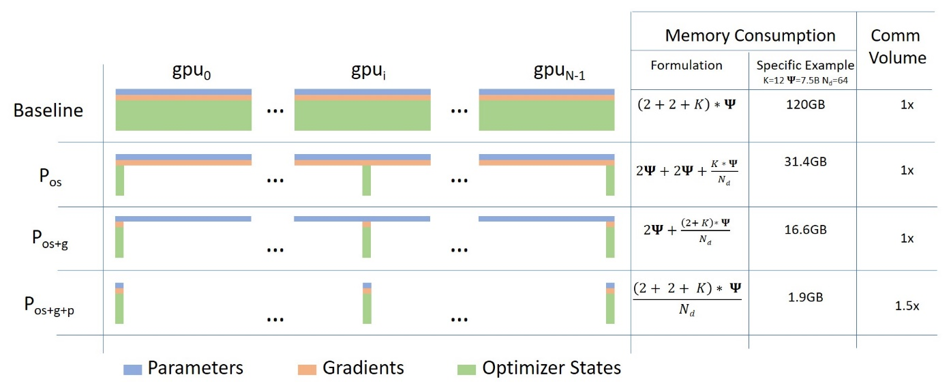
Hugging Face has integrated ZeRO (Zero Redundancy Optimizer) into its libraries, leveraging DeepSpeed and FairScale. This enhancement allows for more efficient training of large language models by reducing memory redundancy across distributed training setups. The optimization enables fitting larger models into memory and accelerating the training process. AI
RANK_REASON Integration of an optimization technique (ZeRO) into popular AI libraries (Hugging Face, DeepSpeed, FairScale) for more efficient LLM training.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →